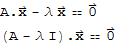 are vectors in
are vectors in
 and
and
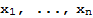 are scalars, then Span[
are scalars, then Span[
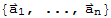 ] :=
] :=
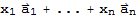 .
.Linear Algebra Notes
By Xah Lee.
Document Created: 1998/03/03.
Last Modified: 1998/07
http://xahlee.org/PageTwo_dir/more.html
1 System of Linear Equations
Solutions to a system of linear equations
There are only 3 possiblilities regarding the solutions to a system of linear equations:
• No solution.
• Exactly one solution.
• Infinitely many solutions.
Definition: Echelon Form, Reduced Echelon form, and Pivot Positions.
A leading entry of a row refers to the leftmost nonzero entry (in a nonzero row).
A rectangular matrix is in echelon form if it has the following two properties:
1. All nonzero rows are above any rows of all zeros.
2. If the leading entry of row n is in column m, then the leading entry for row n+1 must be in column m+1 or greater.
If a matrix in echelon form satisfies the following additional conditions, then it is in reduced echelon form:
1. The leading entry in each nonzero row is 1.
2. Each leading 1 is the only nonzero entry in its column.
The leading entries of a matrix in echelon form are called Pivot Positions.
Existence and Uniqueness Theorem
• Each matrix is row equivalent to one and only one reduced echelon matrix.(†
proof in Appendix)
• A linear system is consistent iff the rightmost column of the augmented matrix is not a pivot column, that is, iff an echelon form of the augmented matrix has no row of the form [0 ... 0 b] with b nonzero.
• If a linear system is consistent, then the solution set contains either (1) a unique solution, when there are no free variables, or (2) infinitely many solutions, when there is at least one free variable.
by Xah: I like to see a (formal) proof of this.
2 Vectors and Matrix Equations
Span
If
are vectors in
and
are scalars, then Span[
] :=
.
Span[
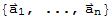 ] is a subset of
] is a subset of
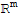 .
.
If Span[
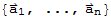 ]==
]==
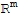 , we say the set of vectors
, we say the set of vectors
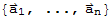 spans
spans
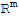 .
.
Definition of A.
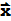
If A is an m × n matrix, with columns
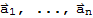 , and
, and
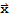 is in
is in
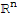 , then the vector A.
, then the vector A.
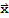 is defined to be
is defined to be
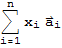 .
.
Equivalent equations
Given an m × n matrix A, with columns
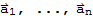 and given
and given
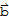 is in
is in
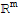 , the following equations all denote the same thing.
, the following equations all denote the same thing.
• The matrix equation
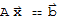
• the vector equation
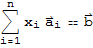
• the system of linear equations whose augmented matrix is
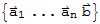
Equivalent Statements
Let A be a m × n matrix. Then the following statements are logically equivalent.
• For each b in
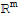 , the equation
, the equation
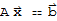 is consistent.
is consistent.
• The columns of A span
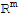 .
.
• A has a pivot position in every row.
By Xah: They are simply logically equivalent statements. Whether they are true is another matter. For (3), think of A as a set of vectors, and a pivot in every row means this set contain all the basis vectors in
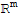 , thus it span
, thus it span
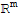 . It is not sufficient if A has a pivot position in every column. Example:
. It is not sufficient if A has a pivot position in every column. Example:
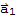 := {1,0,0},
:= {1,0,0},
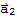 := {0,1,0} does not span
:= {0,1,0} does not span
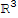 .
.
Distribution Property of Vectors
If A is an m × n matrix,
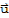 and
and
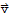 are vectors in
are vectors in
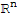 , and c is a scalar, then
, and c is a scalar, then
•
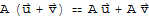
•
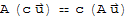
A Theorem on Homogeneous Equation
A system of linear equations is said to be homogeneous if it can be written in the form
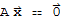 . The homogeneous system
. The homogeneous system
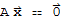 has a nonzero solution iff the system has at least one free variable.
has a nonzero solution iff the system has at least one free variable.
by Xah: This is so because a consistent system either has one unique solution or infinite number of solutions. For the latter, there must be a free variable.
Suppose the equation
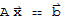 is consistent for some given b, and let
is consistent for some given b, and let
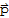 be a solution. Then the solution set of
be a solution. Then the solution set of
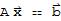 is the set of all vectors of the form
is the set of all vectors of the form
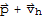 where
where
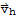 is any solution of the homogeneous equation
is any solution of the homogeneous equation
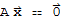 .
.
Proof by Xah: We have
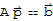 and
and
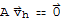
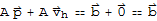
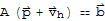
thus
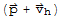 is a solution to
is a solution to
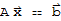 .
.
Now we show that there can be no solution other than
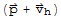 . Suppose
. Suppose
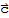 is a solution to
is a solution to
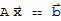 . Then
. Then
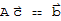
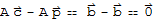
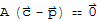
This shows that
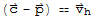 for some
for some
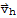
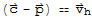
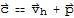
End of proof.
Definition of Linearly Dependence
A set of vectors
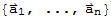 in vector space V is said to be linearly independent if the vector equation
in vector space V is said to be linearly independent if the vector equation
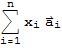 ==
==
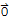
has only the trivial solution
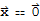 . Otherwise, the set is said to be linearly dependent.
. Otherwise, the set is said to be linearly dependent.
Characterization of Linearly Dependent Sets
• A set S :=
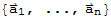 of two or more vectors is linearly dependent iff at least one of the vectors in S is a linear combination of the others.
of two or more vectors is linearly dependent iff at least one of the vectors in S is a linear combination of the others.
• Any set
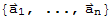 in
in
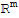 is linearly dependent if n > m.
is linearly dependent if n > m.
• If a set S :=
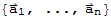 in
in
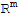 contains the zero vector, then the set is linearly dependent.
contains the zero vector, then the set is linearly dependent.
Problem: Given a set of vectors with one element a linear combination of others. How to determine which one and its linear combination? In general, given a set of vectors, how to determine which vector can be written as a linear combination of which vectors, and which cannot.
Solution:
Solve the equation
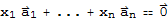
then isolate any term
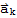 to one side shows its dependence relationship. If
to one side shows its dependence relationship. If
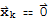 , then it shows the vector
, then it shows the vector
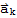 is not a linear combination of other vectors in the set. If
is not a linear combination of other vectors in the set. If
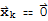 for all k, it agrees with the definition of linearly independent set, no vector is a linear combination of other vectors.
for all k, it agrees with the definition of linearly independent set, no vector is a linear combination of other vectors.
2.5 Intro to Linear Transformation
Linear Transformation
A transformation (or mapping) T is linear if
•
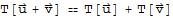 for all
for all
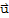 ,
,
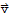 in the domain of T.
in the domain of T.
•
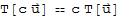 for all
for all
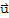 and all scalars c.
and all scalars c.
Theorem: For any linear transformation T,
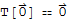 .
.
(this does not mean that
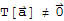 for any
for any
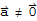 .
.
Stardard Matrix of Linear Transformation
Let T:
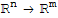 be a linear transformation. Then there exists a unique matrix A such that
be a linear transformation. Then there exists a unique matrix A such that
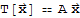 for all
for all
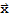 in
in
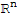 , and
, and
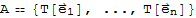
where
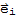 is the ith column of the identity matrix I
is the ith column of the identity matrix I
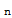 .
.
A is called the standard matrix for the linear transformation T.
(Proof in D.C.Lay 2.6 p.80. Good.)
With this theorem, we could say that every linear transformation from
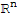 to
to
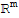 is a matrix transformation, and it's easy to prove that every matrix transformation is linear (see D.C.Lay 2.2 p.52. The one-to-one correspondence of A
is a matrix transformation, and it's easy to prove that every matrix transformation is linear (see D.C.Lay 2.2 p.52. The one-to-one correspondence of A
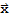 and T[x] is indicated in the book also. see 2.6, exercise 33, p.85. Easy.)
and T[x] is indicated in the book also. see 2.6, exercise 33, p.85. Easy.)
Note, in this theorem, one may think it will have problems when n ≠ m. Not so. Because note that T[e] will return a vector in dimension m.
Onto and one-to-one mapping
• A mapping T:
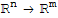 is said to be onto
is said to be onto
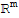 if each
if each
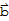 in
in
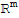 is the image of at least one
is the image of at least one
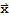 in
in
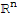 .
.
• A mapping T:
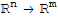 is said to be one-to-one if each
is said to be one-to-one if each
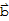 in
in
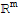 is the image of at most one
is the image of at most one
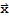 in
in
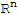 .
.
Let T:
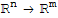 be a linear transformation and let A be the standard matrix for T. Then,
be a linear transformation and let A be the standard matrix for T. Then,
• T maps
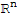 onto
onto
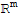 iff the columns of A span
iff the columns of A span
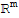 .
.
• T is one-to-one iff the columns of A are linearly independent.
3 Matrix Algebra
3.1 Matrix Operations
Multiplication of Matrices
If A is an m × n matrix, and if B is an n × p matrix, then
A ⊗ B :=
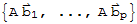 .
.
Motivaton for the definition:
We want the product A⊗B to have the property
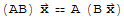 .
.
Now,
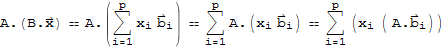
Note that A[x]+A[y]==A[x+y].
The power of A is defined by
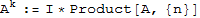 , in particular
, in particular
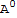 ==I.
==I.
By the definition of matrix multiplication, it follows that the
ith row of (A B)==(ith row of A) times (the matrix B)
Note that the (ith row of A) is a 1 by n matrix.
Transposition of Matrices
The transpose of A is the n × m matrix, denoted by
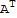 , whose columns are the corresponding rows of A.
, whose columns are the corresponding rows of A.
Note: We can also define Transpose as follows: The transpose of a n × m matrix A is a m × n matrix
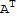 such that Dot[A
such that Dot[A
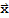 , y]==Dot[
, y]==Dot[
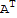 y,
y,
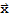 ]. For example, suppose we have A := {{a,b},{c,d}}. Then Dot[A
]. For example, suppose we have A := {{a,b},{c,d}}. Then Dot[A
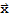 , y] is then
, y] is then
(a x1 + b x2) y1 + (c x1 + d x2) y2
To evalute Dot[
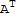 y,
y,
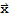 ], we note that it differs from Dot[A
], we note that it differs from Dot[A
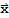 , y] only by the position of the pairs {b,c}, {x1,y1}, {x2,y2} in the final product. So make a switch to get
, y] only by the position of the pairs {b,c}, {x1,y1}, {x2,y2} in the final product. So make a switch to get
(a y1 + c y2) x1 + (b y1 + d y2) x2
Both of them expands to
a x1 y1 + c x1 y2 + b x2 y1 + d x2 y2
This can be expressed and tested in Mathematica as

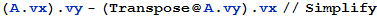
Properties of Matrix Multiplication
Let A be m × n matrix and let B and C have sizes for which the indicated sums and products are defined. Let r be any scalar.
1. A (B C)==(A B) C
2. A (B + C)==A B + A C
3. (B + C) A==B A + C A
4. r (A B)==(r A) B==A (r B)
5.
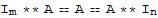
6.
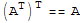
7.
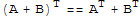
8.
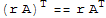
9.
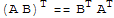
Proofs in D.C.Lay 3.1. Need to see the proof of 9.
My theorem:
Let A be a square matrix and D be a triangular matrix (a matrix with diagonal values and rest zero.)
A D==(D
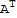 )^T.
)^T.
D A==(
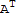 D)^T
D)^T
Note, D is a diagonal matrix. The difference of A D and D A is that D A is like A D except the D comes from above A instead of on the right. Thus it is equals to D
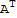 , but we need to transpose them back, so the theorem is A D==(D
, but we need to transpose them back, so the theorem is A D==(D
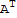 )^T.
)^T.
3.2 The Inverse of a Matrix
Inverse of a Matrix
Let A denote a matrix. The inverse of A is a matrix (written as
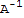 ) such that
) such that
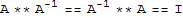
If
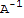 exists, then we say that A is invertible.
exists, then we say that A is invertible.
inverse of 2x2 matirx
Let A := {{a,b},{c,d}}. If a d - b c==0, then A is not invertible, otherwise A is invertible and
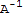 ==1/(a d - b c) {{d,-b},{-c,a}}
==1/(a d - b c) {{d,-b},{-c,a}}
My Proof:
Suppose the column vectors in A are linearly dependent, so that
a==r b
c==r d
for some r. Eliminate r we get a d - b c==0. So if this is true, then column vectors in A are linearly dependent, thus it A has no inverse. If a d - b c != 0, then the column vectors are not linearly dependent, so a inverse exist. In particular, it means the following two systems has solution:
a x1 + b x2==1
c x1 + d x2==0
and
a y1 + b y2==0
c y1 + d y2==1
We solve them by algebra to complete the proof.
Question: Is there a square matrix M or N such that M A==
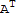 or A N==
or A N==
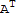 for any square matrix A?
for any square matrix A?
Answer: Not always, for example the matrix A=={{0,1},{0,0}}. If M or N exists, then
M==
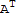
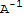 , N==
, N==
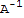
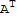 .
.
End of example.
Question: We may think of transposition as a transformation of a one-to-one function of matrix, and the fixed point of this transformation is all the identity matrices. What is the geometric significance of transposition?
To Do:
1) Show that identity matrix is unique. i.e. if E A==A or A E==A, then E==I.
2) Show, or find an example such that M B==N B, but M != N; B M==B N but M != N.
3) Show that for any matrix A, C such that A C==I, then C A==I.
Theorem of Inverses
• If A is an invertible n × n matrix, then for each b in
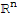 , the equation
, the equation
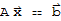 has the unique solution
has the unique solution
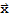 ==
==
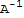 b.
b.
• If A is an invertible matrix, then
1. (
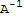 )^-1==A
)^-1==A
2. (
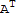 )^-1==(
)^-1==(
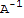 )^T
)^T
• If A and B are n × n invertible matrices, then (A B) is also invertible, and (A B)^-1==
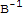
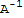
• An n × n matrix A is invertible iff A is row equivalent to In, and in this case, any sequence of elementary row operations that reduces A to In also transforms In to
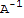 .
.
To Do: Read the proof of this.
My proof of one of the above (the rest is in the book):
(
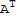 )^-1==
)^-1==
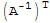
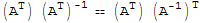
I==(
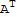 ) (
) (
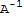 )^T
)^T
I^T==((
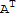 ) (
) (
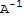 )^T)^T
)^T)^T
I==((
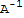 )^T)^T (
)^T)^T (
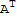 )^T
)^T
I==I
(this proof may be wrong, because it assumed (
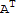 )^-1 exist outright.)
)^-1 exist outright.)
3.3 Characterizations of Invertible Matrices
The Invertible Matrix Theorem
Let A be a square n × n matrix. The following statements are equivalent.
• A is an invertible matrix.
• A is row equivalent to the n × n identity matrix.
• A is a product of elementary matrices.
• The equation
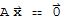 has only the Zero-solution.
has only the Zero-solution.
• The equation
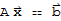 has at least one solution for any b in
has at least one solution for any b in
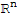 . The equation
. The equation
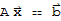 has a unique solution for any b in
has a unique solution for any b in
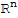 .
.
• The columns of A form a linealy independent set.
• The columns of A span
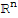 .
.
• The linear transformation T[x] := A
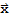 :
:
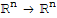 is one-to-one and onto.
is one-to-one and onto.
• There is an n × n matrix C such that A C==I.
• There is an n × n matrix D such that D A==I.
•
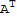 is an invertible matrix.
is an invertible matrix.
• The columns of A forms a basis of
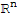 .
.
• Col[A]==
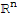 .
.
• Dim[Col[A]]==n.
• Rank[A]==n
• Nul[A]=={
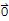 }.
}.
• Dim[Nul[A]]==0.
• The number 0 is not an eigenvalue of A.
5 Vector spaces
5.1 Vector Spaces and Subspaces
Vector Space definition
A Vector Space is a nonempty set V of objects, called vectors, on which are defined two operations, called addition and multiplication by scalars (real or complex), subject to the ten axioms listed below. The axioms must hold for all vectors
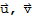 , and
, and
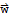 in V and for all scalars c and d.
in V and for all scalars c and d.
1. The sum of
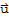 and
and
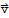 , denoted by
, denoted by
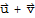 , is in V.
, is in V.
2.
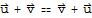 .
.
3.
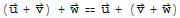 .
.
4. There is a Zero vector
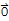 in V such that
in V such that
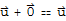 .
.
5. For each
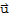 in V there is a vector
in V there is a vector
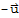 in V such that
in V such that
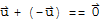 .
.
6. The scalar multiple of
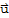 by c, denoted by c
by c, denoted by c
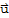 , is in V.
, is in V.
7.
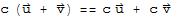 .
.
8.
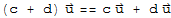 .
.
9.
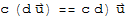 .
.
10.
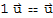 .
.
Alternative definition of a vector space
Let K be a division ring. A vector space over K is an ordered triple {E,+,.} such that {E,+} is an abelian group and . is a function from K × E into E satisfying
•
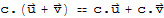
•
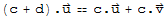
•
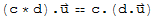
• 1.
for all
 ,
,
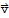 ∈ E and all c, d ∈ K. Elements of E are called vectors, elements of K are called scalars, and . is called scalar multiplication.
∈ E and all c, d ∈ K. Elements of E are called vectors, elements of K are called scalars, and . is called scalar multiplication.
Similarly, {
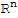 ,+,.} is a vector space over R for each n ∈ N.
,+,.} is a vector space over R for each n ∈ N.
Corollaries
The zero vector
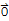 in any vector space is unique, and the vector -
in any vector space is unique, and the vector -
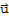 is unique for each
is unique for each
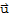 in V, and
in V, and
1. 0*
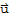 ==
==
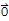
2. c*
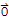 ==
==
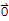
3. -
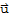 ==(-1)*
==(-1)*
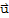
My Proof of -u==(-1)*u.
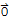 ==0 u (corollary 1)
==0 u (corollary 1)
0 u==(1-1) u (property of arithmetic)
(1-1) u==1 u + (-1) u by axiom 8.
1 u + (-1) u==u + (-1) u by axiom 10. Connection previous equation to get
u + (-1) u==
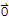
(-u) + u + (-1) u==
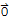 + (-u) Add (-u) to both sides.
+ (-u) Add (-u) to both sides.
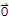 + (-1) u==-u by axiom 4 and 5.
+ (-1) u==-u by axiom 4 and 5.
(-1) u==-u
Subspace of a Vector Space
A subspace of a vector space V is a subset H of V such that H is itself a vector space under the same operations of addition and scalar multiplication that are already defined on V.
Subspace Test
A subset H of vector space V is a subspace of V iff the following conditions are all satisfied:
1. The Zero vector of V is in H.
2. If
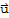 and
and
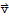 are in H, then
are in H, then
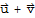 is in H.
is in H.
3. If
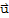 is in H and c is any scalar, then c
is in H and c is any scalar, then c
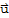 is in H.
is in H.
Spanning Set and Subspace
Given
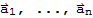 in a vector space V, the set Span[
in a vector space V, the set Span[
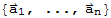 ] is a subspace of V.
] is a subspace of V.
We call Span[
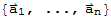 ] the subspace generated by
] the subspace generated by
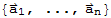 . Given any subspace H of V, a spanning set for H is a set
. Given any subspace H of V, a spanning set for H is a set
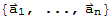 in H such that H==Span[
in H such that H==Span[
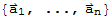 ].
].
5.2 Null Spaces, Column Spaces, and Linear Transformations
Null Space
Given an m × n matrix A, the null space of A (denoted Nul[A]) is the set of all solutions to the homogeneous equation
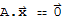 . In set notation,
. In set notation,
Nul[A] := {
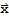 :
:
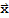 is in
is in
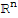 and
and
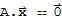 }
}
Nul[A] is the set of all
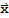 in
in
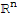 that are mapped into the zero vector of
that are mapped into the zero vector of
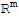 by the linear transformaiton A.
by the linear transformaiton A.
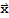 .
.
Column Space
Given an m × n matrix A, the column space of A (denoted Col[A]) is the set of all linear combinations of the columns of A. In set notation,
Col[A] := {
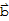 :
:
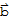 is in
is in
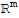 and
and
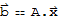 for some
for some
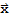 in
in
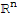 }
}
Column space is just the range of a linear transformation.
The null space of an m × n matrix A is a subspace of
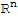 .
.
The column space of an m × n matrix A is a subspace of
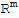 .
.
When talking about linear transformation, null space and column space are often called kernel and range respectively. Kernel is the set of
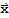 such that T[x]==
such that T[x]==
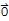 , and range has the usual meaning for a function — all possible outputs.
, and range has the usual meaning for a function — all possible outputs.
5.3 Linearly Independent Sets; Bases
definition: Linearly Independence
A Set
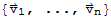 of two or more vectors, with
of two or more vectors, with
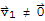 , is linearly dependent iff some
, is linearly dependent iff some
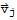 (with j > 1) is a linear combination of the preceding vectors.
(with j > 1) is a linear combination of the preceding vectors.
We require
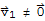 because, suppose we have an ordered set S :=
because, suppose we have an ordered set S :=
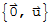 . This is a linearly dependent set by definition, but there are no
. This is a linearly dependent set by definition, but there are no
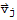 (with j > 1) that is a linear combination of the preceding vectors,
(with j > 1) that is a linear combination of the preceding vectors,
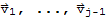 ; in other words,
; in other words,
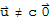 . On the other hand, if S :=
. On the other hand, if S :=
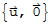 , we have
, we have
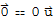 , thus showing S is linearly dependent as the theorem dictates.
, thus showing S is linearly dependent as the theorem dictates.
Question: why can't the definition be that "there are no vector that is a linear combination of two or more vectors in the set?"
definition: Basis of a Vector Space
Let H be a subspace of a vector space V. Let B be a set of vectors in V. B is a basis for H if
1. B is a linearly independent set.
2. the subspace spanned by B is equal to H.
Note: the set {
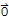 } do not have a basis because {
} do not have a basis because {
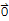 } is dependent by definition.
} is dependent by definition.
• Let
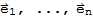 be the columns of the n × n identity matrix In. The set
be the columns of the n × n identity matrix In. The set
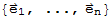 is called the standard basis for
is called the standard basis for
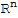 .
.
The Spanning Set Theorem
Let S :=
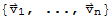 be a set in vector space.
be a set in vector space.
• Suppose
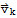 in S is a linear combination of the remaining vectors, and S2 is a set formed by removing the element
in S is a linear combination of the remaining vectors, and S2 is a set formed by removing the element
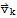 from S, then Span[S]==Span[S2].
from S, then Span[S]==Span[S2].
• If Span[S] ≠ {
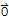 }, some subset of S is a basis for Span[S].
}, some subset of S is a basis for Span[S].
Note: S do not have a basis if S := {
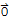 }. That's why we require Span[S]≠{
}. That's why we require Span[S]≠{
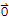 } in the theorem.
} in the theorem.
Basis of Col[A]
The pivot columns of a matrix A forms a basis for Col[A].
The following theorem is "my own". It's incomplete. I need to complete the theorem statement and proof.
Let V and W be vector spaces, let T: V → W be a linear transformation, and let S:=
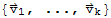 be a subset of V, and
be a subset of V, and
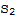 :=
:=
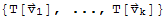 .
.
• If S is linearly dependent in V, then
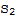 is linearly dependent in W.
is linearly dependent in W.
• If
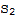 is linearly independent in V, then S is linearly dependent in W. ???
is linearly independent in V, then S is linearly dependent in W. ???
If T is one-to-one transformation, then
• S is linearly dependent iff
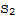 is linearly dependent.
is linearly dependent.
• S is lineary independent iff
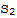 is linearly independent.
is linearly independent.
My Proof:
Suppose S is linearly dependent. Whether S2 is linearly dependent depends on whether c1==c2==...==ck==0 is the only solution to the equation
c1 T[v1] + c2 T[v2] +... + ck T[vk]==
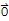 iff
iff
T[c1 v1] + T[c2 v2] +... + T[ck vk]==
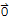 iff
iff
T[c1 v1 + c2 v2 +... + ck vk]==
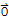 iff
iff
(c1 v1 + c2 v2 +... + ck vk==
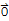 or T[b]==
or T[b]==
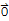 for some b ≠
for some b ≠
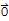 )
)
The theroems above easily follows from here.
A vector equation of the form c1 v1 + c2 v2 +... + ck vk==b has either one solution, infinitely many solution, or no solution. Need to see a proof. To Do.
5.4 Coordinate Systems
theorem: The Unique representation
Let B :=
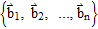 be a basis for a vector space V. Then for each
be a basis for a vector space V. Then for each
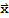 in V, there exists a unique set of scalars
in V, there exists a unique set of scalars
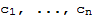 , such that
, such that
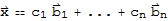 .
.
Proof:
Suppose there are two representations x == Sum[ci*bi,{i,n}] and x == Sum[di*bi,{i,n}].
Subtract the equations we have
zeroVector == Sum[(ci-di)*bi,{i,n}]
Since all bi are linearly independent, thus all (ci-di) must be 0, which means ci==di for all i.
Definition: Coordinates
Suppose the set B :=
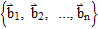 is a basis for V and
is a basis for V and
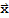 is in V. The Coordinates of
is in V. The Coordinates of
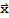 relative to the basis B are the weights
relative to the basis B are the weights
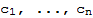 such that
such that
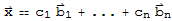 .
.
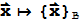 is one-to-one and onto
is one-to-one and onto
Let B :=
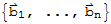 be an ordered basis for a vector space V. Then the coordinate mapping
be an ordered basis for a vector space V. Then the coordinate mapping
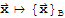 is a one-to-one linear transformation from V onto
is a one-to-one linear transformation from V onto
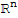 .
.
5.5 The Dimension of a Vector Space
Number of Vectors in Basis
• If a vector space V has a basis B:=
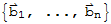 , then any set in V containing more than n vectors must be linearly dependent.
, then any set in V containing more than n vectors must be linearly dependent.
• If a vector space V has a basis of n vectors, then every basis of V must consist of exactly n vectors.
Dimension of V
If V is spanned by a finite set, then V is said to be finite-dimensional, and the dimension of V, written as dim[V], is the number of vectors in a basis for V. The dimension of zero vector space {
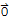 } is defined to be zero. If V is not spanned by a finite set, then V is said to be infinite-dimensional.
} is defined to be zero. If V is not spanned by a finite set, then V is said to be infinite-dimensional.
Linear Dependence, Span, Dimension and Basis
• Let H be a subspace of a finite-dimensional vector space V. Any linearly independent set in H can be expanded, if necessary, to a basis for H. Also, H is finite-dimensional and dim[H] ≤ dim[V].
• Let V be an n-dimensional vector space, n ≥ 1, and let S be a subset of V that contains exactly n elements. Then:
* If S is linearly independent, then S is a basis for V.
* If S spans V, then S is a basis for V.
The dimension of Nul[A] is the number of free variables in the equation
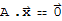 , and the dimension of Col[A] is the number of pivot columns in A.
, and the dimension of Col[A] is the number of pivot columns in A.
5.6 Rank
Basis for Row Spaces
If two matrices A and B are row equivalent, then their row spaces are the same. If B is in echelon form, the nonzore rows of B form a basis for the row space of A as well as B.
Rank
The rank of A is the dimension of the column space of A.
The dimensions of the column space and the row space of an m × n matrix A are equal. This common dimension, the rank of A, also equals the number of pivot positions in A and satisfies the equation
Rank[A] + Dim[Nul[A]]==n
6 Eigenvectors and Eigenvalues
6.1 Eigenvectors and Eigenvalues
Eigenvector and Eigenvalue
An eigenvector of an n × n matrix A is a nonzero vector
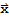 such that
such that
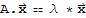 for some scalar λ. A scalar λ is called an eigenvalue of A if there is a vector
for some scalar λ. A scalar λ is called an eigenvalue of A if there is a vector
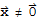 such that
such that
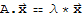 ; such an
; such an
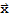 is called an eigenvector corresponding to λ.
is called an eigenvector corresponding to λ.
Eigenspace:
Suppose
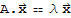 , then
, then
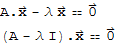
The null space of (A-λ I) is called the eigenspace of A corresponding to λ.
triangular matrix and eigenvalue
Let A be a triangular matrix. Then the eigenvalues of A are the entries on its main diagonal.
Proof is easy. Look at the matrix (A-λ*I). The column vectors in this matrix must be linearly independent, and the only way is for λ to equal to some of the diagonal entries.
Linear independence of engine vectors
If
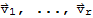 are eigenvectors that correspond to distinct eigenvalues
are eigenvectors that correspond to distinct eigenvalues
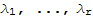 of an n × n matrix A, then the set
of an n × n matrix A, then the set
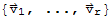 is linearly independent.
is linearly independent.
Proof:
If
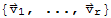 is linearly dependent, then there is a least index p such that
is linearly dependent, then there is a least index p such that
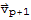 is a linear combination preceding (linearly independent) vectors, and there exist scalars
is a linear combination preceding (linearly independent) vectors, and there exist scalars
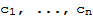 such that
such that
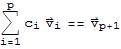 (*5*)
(*5*)
Multiplying both sides by A and using the fact that
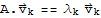 for each k, we obtain
for each k, we obtain
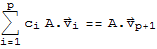
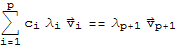 (*6*)
(*6*)
Multiplying both sides of (*5*) by
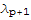 and subtracting the result from (*6*), we have
and subtracting the result from (*6*), we have
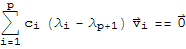 (*7*)
(*7*)
Since
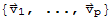 is linearly independent, the weights in (*7*) are all zero. But none of the factors
is linearly independent, the weights in (*7*) are all zero. But none of the factors
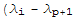 ) are zero, because the eigenvalues are distinct. Hence
) are zero, because the eigenvalues are distinct. Hence
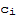 ==0 for i=1,...,p. But then (*5*) says that
==0 for i=1,...,p. But then (*5*) says that
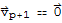 , which is impossible. Hence
, which is impossible. Hence
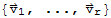 cannot be linearly dependent and therefore must be linearly independent.
cannot be linearly dependent and therefore must be linearly independent.
6.2 The Characteristic Equation
Determinant
One way to define determinants is as follows: For an n × n matrix. We row reduce it to echelon form using the following methods:
* Replace a row by the linear combination of other rows.
* Interchange a row with another row.
(in particular, scaling of a row by itself is not allowed.)
The determinants of A is the product of the diagonal entries times
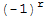 , where r is the number of times we interchanged rows.
, where r is the number of times we interchanged rows.
If the matrix is not invertible, it will contain a 0 in its diagonal, and thus the determinant will be 0.
If A is a 3 × 3 matrix, then Abs[Det[A]] is the volume of the parallelepiped defined by the column vectors of A.
Properties of Determinants
Let A and B be an n × n matrices.
• A is invertible iff Det[A] ≠ 0
• Det[A.B]==Det[A]*Det[B]
• Det[
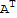 ]==Det[A]
]==Det[A]
• If A is triangular, then Det[A] is the product of the entries on the main diagonal of A.
• A row replacement operation on A does not change the determinant. A row interchange changes the sign of the determinant. A row scaling also scales the determinant by the same scalar factor.
Proofs in D.C.Lay, chapter 4.
characteristic polynomial
The scalar equation Det[A - λ*I]==0 is called the characteristic equation of A.
A scalar λ is an eigenvalue of an n × n matrix A iff λ satisfies the characteristic equation Det[A - λ I]==0.
This is so because:
A.x==λ*x
A.x-λ*x==0
A.x-λ*I.x==0
(A-λ*I).x==0.
similar matrixes
If A and B are n × n matrices, then A is similar to B if there is an invertible matrix P such that
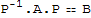 . (which implies A==P.B.P^-1)
. (which implies A==P.B.P^-1)
Xah's note: I think: in group theory, this idea is called conjucate class. i.e. two elements a and b are in the same conjucate class if there exist a element p, such that p^-1*a*p==b.
theorem: similar matrixes has the same eigensystem
If n × n matrices A and B are similar, then they have the same characteristic polynomial and hence the same eigenvalues.
Proof: If B==
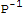 .A.P, then
.A.P, then
B-λ*I==
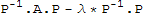 ==
==
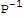 .(A.P-λ*P)==
.(A.P-λ*P)==
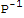 .(A-λ*I).P
.(A-λ*I).P
using the multiplicative property of determinants, we have
Det[B-λ*I]==Det[
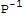 .(A-λ*I).P]==Det[
.(A-λ*I).P]==Det[
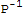 ]*Det[(A-λ*I)]*Det[P]==Det[
]*Det[(A-λ*I)]*Det[P]==Det[
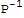 ]*Det[P]*Det[(A-λ*I)]==Det[
]*Det[P]*Det[(A-λ*I)]==Det[
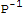 .P]*Det[(A-λ*I)]==Det[(A-λ*I)]
.P]*Det[(A-λ*I)]==Det[(A-λ*I)]
Some common algorithms for estimating the eigenvalues of a matrix is based on the above theorem. They include QRDecomposition and Jacobi's method. See p.287 of David C.Lay.
Diference equations and dynamic systems
Eigensystem is the key to difference equations and dynamic systems. For example, we are given the vector sequence
f[0]:=
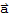
f[n]:=A.f[n-1]
This sequence can be written as
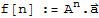
One can avoid the multiplication of matrices by using eigensystems. Suppose A is 2 × 2 and we have the eigensystems
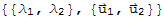 .
.
Remember that A^n.x==λ^n.x for eigensystem λ and x.
Write
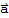 in terms of eigenvectors (this can be done since the eigenvectors forms a basis). Suppose we have
in terms of eigenvectors (this can be done since the eigenvectors forms a basis). Suppose we have
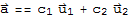
Now,
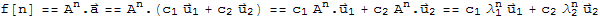
thus
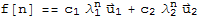
This is a closed form of f[n]. The closed form facilitate computation and analysis of the behavior of f[n]. We may use it to find Limit[f[n],n->Infinity].
6.3 Diagonalization
definition: Diagonalization
A square matrix A is said to be diagonable if A is similiar to a diagonal matrix, that is, if A==P.D.P^-1 for some invertible matrix P and some diagonal matrix D.
theorem: Diagonalization
An n × n matrix A is diagonalizable iff A has n linealy independent eigenvectors.
If A==P.D.P^-1 where D is diagonal, then the diagonal entries of D are eigenvalues of A and the columns of P are the corresponding eigenvectors.
Proof:
Let u1, u2,... be independent eigenvectors of A, and λ1, λ2,... be the corresponding eigen values.
We have
[A.u1 A.u2 ...]==[λ1*u1 λ2*u2 ...] (*1*)
which can be rewriten as
A.P==P.D
by the given definition of matrix P and D. Since ui are independent, P^-1 exist. Right multiply both sides by P^-1 we have
A==P.D.P^-1
This proves the half of first part of the theorem. Now, if given A==P.D.P^-1 for some P, D, we can use (*1*) to show that A.ui==ci*ui by equating columns. Now, since ui for all i are independent and none are zero vectors, it shows that ci are eigenvalues corresponding to the eigenvectors ui.
The second part of the theorem is also proven in the process.
End of proof.
theorem
Let A be an n × n matrix whose distinct eigenvalues are λ_1,...,λ_p. For k:=1,...,p, let B_k be a basis for the eigenspace corresponding to λ_k. Let B be the union of B_1,...,B_p. Then B is linearly independent.
Notes: recall that eigenspace of an eigenvalue λ is defined to be all eigenvectors that has λ as their eigenvalue. That is to say, an eigenvalue may have more than one linearly independent eigenvectors. The theorem does not say an n × n matrix will always have n eigenvectors. If only says that if A has n linearly independent eigenvectors, then A is diagonalizable.
Proof: (need editing)
Suppose λ_1,...,λ_n are the distinct eigenvalues of matrix A. Suppose B_i are eigenvector bases corresponding to λ_i and each B_i has dimensions Length[B_i].
Let s_i be :=Sum[c_i_j*B_i[[j]],{j,Length[B_i]}].
surfeit to say that if Sum[s_i,{i,n}]==zeroVector, then s_i==0 for all i. This is so because eigenspace of different eigenvalues has no intersection. Thus, the above implies all c_i_j==0 in
Sum[c_i_j*B_i[[j]],{j,Length[B_i]}]==zeroVector
Which inplies all c_i_j==0 in
Sum[(c_i_j*B_i[[j]]),{i,n},{j,Length[B_i]}]==zeroVector
Thus B is linearly independent.
--------------------------------
are all zero.
We know that c_j==0 in Sum[(c_j),B_i[[j]],{j,n}]==zeroVetor.
Sum[Sum[(c_i_j*B_i[[j]]),{j,Length[B_i]}],{i,n}]
Suppose b_i_m is an eigenvector in B_i.
Sum[Plus@@(c_i_j*B_i),{i,n}]==zeroVector
and all c_i_j must be zero.
This means each of Plus@@(c_i_j*B_i)==zeroVector.
6.4 Eigenvectors and Linear Transformation
theorem: Diagonal Matrix Representation
Suppose A:=P.D.P^-1, where D is a diagonal x × n matrix. If B is the basis for
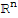 formed from the columns of P, then D is the B-matrix of the transformation
formed from the columns of P, then D is the B-matrix of the transformation
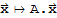 .
.
Proof: (verbatim from the book. Needs editing.)
Denote the columns of P by b_1,...,b_n, so that B={b_1,...,b_n}, and P=[b_1 ... b_n]. In this case P is the change-of-coordinates matrix P_B discussed in Section 5.4, where
P[X]_B == x and [x]_B==(P^-1).x
If T[x]==A.x for x in R^n, then
[T]_B==[[T[b_1]]_B ... [T[b_n]]_B]
==[[A.b_1]_B ... [A.b_n]_B]
==[(P^-1).A.b_1 ... (P^-1).A.b_n]
==(P^-1).A.[b_1 ... b_n]
==(P^-1).A.P
Since A==P.D.(P^-1), we have [T]_B==(P^-1).A.P==D.
6.5 Complex Eigenvalues
linear map of an abstract vector space (xah's note)
To define a linear map T, we don't have to know the image of every element in V. We only need to know the image of a set of vectors that is a basis for V. This is so because the property of linear map that L[a+b]==L[a]+L[b] and L[α*a]==α*L[a]. In particular, every vector can be written as linear combinations of the basis vectors, thus we can find their image. (Greek letter denote scalars.)
It is extremely convenient to find the isomorphism between an abstract linear space and the linear space in R^n, because the latter can be computed more easily, and linear map can be written as matrixes.
The following describes the method of finding an isomophic vector space in R^n from a given abstract vector space.
Given a n dimensional linear space {V,+,*} over R^1. Suppose B is a basis. A linear mapping T is defined by specifying the images of basis vectors. i.e., we know the value of T[b[k]] for 1<=k<=n. Let us use B as the coordinate basis. We want to find the matrix A corresponding to T. Let {b[k]} denote the coordinates of b[k] with respect to basis B. Let {e[k]} denote the standard basis, that is: {e[1]}=={1,0,0,0,...}, {e[2]}={0,1,0,0,...}, etc. The coordinates of b[k] with respect to B is {e[k]}, i.e. {b[k]}=={e[k]}.
Now, the coordinates of T[{b[k]}] can be denoted as {T[{b[k]}]}.
Let x be a vector in R^n. x[i] be its ith coordinates. We can write x as Sum[x[i]*{e[i]},{i,1,n}]. Now,
T[x]==T[Sum[x[i]*{e[i]},{i,1,n}]]==Sum[x[i]*T[{e[i]}],{i,1,n}]
Thus we see that kth column of matrix A is {T[{b[k]}]}.
7 Orthogonality and Least-squares
7.1 Inner Product, Length, And Orthogonality
Inner product definition
The inner product of vectors u and v in R^n is defined to be Sum[u[i]*v[i],{i,1,n}], where u[i] and v[i] are the elements in u and v.
Properties of inner product
Let u, v, and w be vectors in R^n, and let c be a scalar.
u.v==v.u
(u+v).w==u.w+v.w
(c*u).v==c(u.v)==u.(c.v)
u.u>=0, and u.u = 0 iff u==
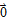 .
.
Length of a vector
The length (or norm) of
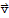 is the nonnegative scalar {|
is the nonnegative scalar {|
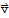 |} defined by
|} defined by
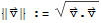
Distance
For
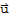 and
and
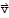 in
in
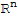 , the distance between them is defined to be {|
, the distance between them is defined to be {|
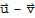 |}.
|}.
Orthogonality
Two vectors u and v in R^n are orthogonal (to each other) if u.v==0.
The motivation for this definion:
We want to look at vectors as lines in Euclidean space, and define orthogonality as being perpendicularity. Suppose u and v are vectors. They are orthogonal if the distance from u to v and u to -v are equal. Using Pythagorean theorem, the distance from u to v is
{|u-v|}=={|u|}^2 + {|v|}^2 - 2*u.v
The distance from u to -v is
{|u+v|}=={|u|}^2 + {|v|}^2 + 2*u.v
we see that they are equal iff u.v==0.
Pythogorean Theorem
Two vectors u and v are orthogonal iff {|u+v|}^2=={|u|}^2+{|v|}^2
(this follows directly from defitions)
Orthogonal Complements
Let W be a subspace of R^n, let z be a vector. If z is orthogonal to every vector in W, then z is said to be orthogonal to W. The set of vectors that are orthogonal to W is called the orthogonal complement of W, written as W^⊥ or ⊥[W].
theorem:
A vector v is in ⊥[W] iff v is orthogonal to all vectors in a set that spans W.
Proof:
Let {a1,...,an} be a set of basis vectors for a subspace W of R^n.
Given: v is orthogonal to ai for all i. This means ai.v==0 for all i.
We want to prove that v is orthogonal to any linear combinations af ai. This means
Sum[ci*ai,{i,n}].v==0
where ci are scalars. By properties of inner product, the equation is equivalent to
Sum[(ci*ai).v,{i,n}]==0
Sum[ci*(ai.v),{i,n}]==0
Sum[ci*0,{i,n}]==0
This proves half of the first statement.
If b.v==0 for all b in W, then it means
Sum[(ci*ai),{i,n}].v==0
by inner product property,
ci*ai.v==0 for all i.
ai.v==0
End of proof.
dimensions of ⊥[W]
Let W be any vector space. The dimension of ⊥[W] is 1.
Proof:
Let x be a non-zero vector in W. Suppose b1, b2 are basis vectors in ⊥[W], thus ⊥[W] has dimension 2.
If follows that b1.x==0, b2.x==0, and (b1+b2).x==0. Combine the equations we have
(b1+b2).x==b1.x
For vectors u1,u2,v, u1.v==u2.v iff u1==u2, thus
b1+b2==b1
b2==zeroVector
but this cannot be because basis vectors cannot be zero vectors. Thus, b1 and b2 cannot be a basis for ⊥[W], and ⊥[W] cannnot have dimension 2. Similarly, if b1, b2, b3 are basis for ⊥[W], we can show that (b1+b2+b3)==b1, b2+b3==zeroVector, and this cannot be because b2 and b3 are independent. Similarly, ⊥[W] cannot have dimensions greater than 1.
Theorem: Orthogonality, row space, null space, and column space
Let A be an m × n matrix. Then the orthogonal complement of the row space of A is the nullspace of A, and the orthogonal complement of the column space of A is the nullspace of T[A]. In symbols,
⊥@Row[A]==Nul[A], ⊥@Col[A]==T@Nul[A]
Proof
The row-column rule for computing A.x shows that if x is in Nul A, then x is orthogonal to each row of A (with the rows treated as vectors in R^n). Since the rows of A span the row space, x is orthogonal to Row A. Conversely, if x is orthogonal to Row A, then x is certainly orthogonal to the rows of A, and hence A.x==0. This proves the first statement. Thesecond statemenfollows from the first by replacing A with T[A] and using the fact that Col[A]==T@Row[A].
7.2 Orthogonal Sets
orthogonal set and linear independence
A set of vectors {u1, ... ,up} in
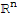 is said to be an orthogonal set if each pair of distinct vectors from the set is orthogonal, that is, if ui.uj==0 whenever i≠j.
is said to be an orthogonal set if each pair of distinct vectors from the set is orthogonal, that is, if ui.uj==0 whenever i≠j.
If S=
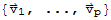 is an orthogonal set of nonzero vectors in
is an orthogonal set of nonzero vectors in
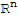 , then S is linearly independent.
, then S is linearly independent.
Proof:
We want to show that the only solution to the equation
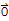 ==
==
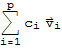 is for
is for
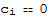 for all i. Multiply both sides by
for all i. Multiply both sides by
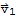 to obtain
to obtain
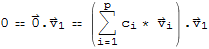
by distribution property, we have
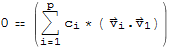
Since elements of S are pairwise orthogonal, their dot product is 0, thus we have
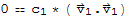
which shows that
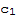 is 0. Similarly, all other scalers must be 0. End of Proof.
is 0. Similarly, all other scalers must be 0. End of Proof.
computing coordinates wrt a given orthogonal basis
Let
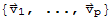 be an orthogonal basis for a subspace W of
be an orthogonal basis for a subspace W of
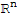 . Let
. Let
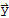 be a vector in W. The coordinates of
be a vector in W. The coordinates of
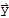 with respect to the basis is
with respect to the basis is
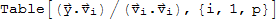 .
.
Proof:
we want to show that
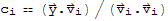 is a solution to the equation
is a solution to the equation
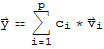 .
.
To solve the equation, dot both sides by
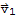 , we get
, we get
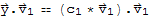
(most vector terms are eliminated because their dot product is zero)
Isolate
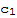 to solve one coordinate. Other coordinates can be solved similarly.
to solve one coordinate. Other coordinates can be solved similarly.
orthonormal set
A set {u1, ... ,up} is an orthonormal set if it is an orthogonal set of unit vectors.
An m × n matrix U has orthonormal columns iff (T@U).U==I.
Proof: (See D.C.Lay)
The proof for the general matrix is tedious, though not much insight. Essentially, the steps are to carry out the product showing each matrix entry in detail, and show that in order for the columns in U to be orthonormal, certain product of elements must be 0 or 1, and when this occurs, the whole thing equals to the identity matrix.
length and orthogonality invarience
Let U be an m × n matrix with orthonormal columns, and let
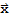 and
and
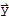 be in
be in
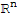 . Then
. Then
(a) {|U.
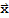 |}==|}x{|
|}==|}x{|
(b) (U.
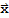 ).(U.y)==
).(U.y)==
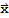 .
.
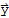
(c) (U.
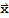 ).(U.y)==0 iff
).(U.y)==0 iff
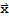 .
.
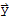 ==0.
==0.
Property (a) and (c) say that the linear mapping
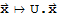 preserves lengths and orthogonality. Proof should be easy.
preserves lengths and orthogonality. Proof should be easy.
7.3 Orthogonal projection
The orthogonal Decomposition theorem
Let W be a subspace of
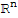 that has an orthogonal basis. Then each
that has an orthogonal basis. Then each
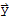 in
in
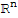 can be written uniquely in the form
can be written uniquely in the form
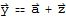 <<1>>
<<1>>
where
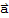 is in W and
is in W and
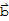 is in ⊥@W. In fact, if
is in ⊥@W. In fact, if
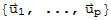 is any orthogonal basis of W, then
is any orthogonal basis of W, then
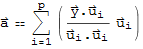 <<2>>
<<2>>
and
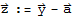
Proof:
Let
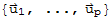 be an orthogonal basis of W, and define
be an orthogonal basis of W, and define
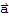 as in the theorem. Clearly,
as in the theorem. Clearly,
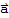 is in W because
is in W because
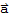 is a linear combination of the basis
is a linear combination of the basis
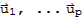 . Let
. Let
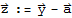
Since
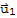 is orthogonal to
is orthogonal to
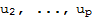 , it follows from <<2>> that
, it follows from <<2>> that
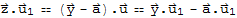
substitute
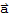 by its definition, and distribute, we have
by its definition, and distribute, we have
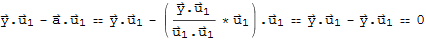
thus
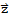 is orthogonal to
is orthogonal to
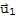 . Similarly, z is orthogonal to each uj in the basis for W. Hence z is orthogonal to veery vector in W. This is, z is in ⊥@W.
. Similarly, z is orthogonal to each uj in the basis for W. Hence z is orthogonal to veery vector in W. This is, z is in ⊥@W.
To show that decomposition in <<1>> is unique, suppose that y can also be written as y==a1+z1, with a1 in W and z1 in W^⊥. Then a+z== a1+z1 (since both sides equal y), and so
a-a1==z1-z
This equality shows that the vector v==a-a1 is in W and in W^+. (because z1 and z are both in W^+, and W^+ is a subspace) Hence v.v==0, which shows that v==zero. This proves that a==a1, and also z1==z.
Property of orthogonal projection:
Let W=Span[{u1,...,up}]. Let y be a vector in W. Projection[y,W]==y.
The best approximation theorem
Let W be a subspace of R^n, y by any vector in R^n, and va be the orthogonal projection of y onto W determined by an orthogonal basis of W. Then va is the closest point in W to y, in the sense that
||y-va||<||y-v|| <<3>>
for all v in W distinct from y.
Proof: Take v in W distinct from va. Then v-va is in W. By the Orthogonal Decomposition Theorem, y-va is orthogonal to W. In particular, y-va is orthogonal to v-va. Since
y-v==(y-va)+(va-v)
The Pythagorean theorem gives
(||y-v||)^2==(||y-va||)^2+(||va-v||)^2
Now (||va-v||)^2>0 because va-v=!=zero, and so the inequality in <<3>> is clear.
If {u1,...,up} is an orthonormal basis for a subspace W of R^n, then
Projection[y,W]==Sum[(y.ui)*ui,{i,1,p}] <<4>>
Let the matrix U has column vectors u1,...,up. Then,
Projection[y,W]==U.U^t.y, for all y in R^n. <<5>>
Proof:
Formula <<4>> follows immediates from <<2>>. Also, <<4>> shows that projection[y,W] is a linear combination of the columns of U using the weights y.ui. The weights may be written as u^T_i, showing that they are the entries in U^T.y and justifying <<5>>.
7.4 The Gram-Schmidt process
7.4 The Gram-Schmidt process
Given a basis {x1,...,xp} for a subspace W of R^n, define
v_1:=x_1
v_p:=x_p - Sum[((x_p.v_i)/(v_i.v_i))*v_i,{i,1,p-1}]
Then {v1,...,vp} is an orthogonal basis for W. In addition,
Span[{v1,...,vk}]==Span[{x1,...,xk}] for 1<=k<=p.
Proof:
For 1<=k<=p, let W_k:=Span[{x1,...,xk}]. Set v1:=x1, so that Span[{v1}]==Span[{x1}]. Suppose that for some k wehave constructed v1,...,vk so that {v1,...,vk} is an orthogonal basis for W_k. Define
v_(k+1)==x_(k+1)-Projection[x_(k+1),W_k]
Note that Projection[x_(k+1),W_k] is in W_k and hence alsoin W_(k+1). Since x_(k+1) is in W_(k+1), so is v_(k+1). Furthermore, v_(k+1)!=zero because x_(k+1) is not in W_k:=Span[{x1,...,xk}]. Hence {v1,...,v_(k+1)} is an orthogonal set of nonzero vectors in the (k+1)-dimensional space W_(k+1). By a therome about number of indepedent vectors spans n-dimensional space, this set is an orthogonal basis for W_(k+1). Hence W_(k+1)==Span[{v1,...,v_(k+1)}]. After p steps, the process stops.
Idea:
The idea of Gram-Schmidt process is to use projection to go through each of the vectors. For each vector, project it onto the space previously found, thus obtaining a orthogonal basis one by one.
QR Factorization
If A is an m x n matrix with linearly independent columns, then A may be factored as A==Q.R, where Q is an m x n matrix whose columns form an orthonormal basis for Col A and R is an n x n upper triangular invertible matrix with positiveentries on its diagonal.
Proof: The columns of A form a basis {x1,...,xn} for Col A. Construct an orthonormal basis {v1,...,vn} for W=Col A with property <<1>> in theorem 11. This basis may be constructed by the Gram-Schmidt process or some other means. Let
Q:={v1 v2 ... vn}
For k:=1,...,n, x_k is in Span[{x1,...,xk}]==Span[{v1,...,vk}]. So there are constants, r_1k,...,r_kk, such that
x_k==r_1k*v_1+...+r_kk*v_k+0.v_(k+1)+...+0.v_n
we may assume that r_kk >=0. (if r_kk<0, multiply both r_kk and v_k by -1) This shows that x_k is a linear combination of the columns of Q using as weights the entries in the vector
r_k:={r_1k,...,r_kk,0,...,0}
That is, x_k==Q.r_k for k:=1,...,n. Let R:={r1,...,rn}. Then
A=={x1,...,xn}==[Q.r_1,...,Q.r_n]==QR
The fact that R is invertible follows easily from the fact that the columns of A are linearly independent. Since R is clearly upper triangular, its nonnegative diagonals entries must be positive.
Questions
number of eigen values
What is the relation between a given square (real) matrix and the number of (real) eigen values it has? (I suppose if complex numbers and multiplicity are counted, then it's always the same as the dimension of the matrix?)
prove or study: The set of eigenvectors always spans row space?
Suppose A is a n × n matrix. I think that if we allow complex eigen values, then A always have n independent eigenvectors.
characteristic polynomial
What is the relation between characteristic polynomial and matrix without using determinants? i.e. I wish to see the connection of linear mapping and its characteristic polynomial, through aspects other than incomprehensible determinants or row reduction.
From: Robin Chapman <rjc@maths.ex.ac.uk>
Newsgroups: sci.math
Subject: Re: matrix and its polynomial
Date: Wed, 24 Jun 1998 07:49:18 GMT
Organization: University of Exeter
In article <yo33ecvwu5a.fsf@shell13.ba.best.com>,
Xah Lee <xah@shell13.ba.best.com> wrote:
> * How to define the characteristic polynomial of a square matrix
> without involving determinants?
Let A be an n by n matrix over a field k. The characteristic polynomial of
is the product of (X - a_j)^(n_j) where the a_j are the distinct eigenvalues
of A over an algebraic closure of k, and n_j is the dimension of the
nullspace of (A - a_j I)^n.
Robin Chapman + "They did not have proper
Department of Mathematics - palms at home in Exeter."
University of Exeter, EX4 4QE, UK +
rjc@maths.exeter.ac.uk - Peter Carey,
http://www.maths.ex.ac.uk/~rjc/rjc.html + Oscar and Lucinda
Relation between Null space and Column space
There is a theorem in basic linear algebra that says:
"Let A be an m × n matrix. Then the orthogonal complement of the row space of A is the nullspace of A."
Is there a geometric insight that makes this apparant?
Transposition as a linear function
• Is there a square matrix B such that B A==
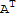 for any square matrix A?
for any square matrix A?
Partial Answer: It seems yes.
To Do: Prove this, and find a general formula for B given A.
• Can we think of transposition of square matrices as one-to-one function for such matrices, and the fixed point of this function is all the identity matrices.
My Answer: Yes.
vector space always a sub space?
Is a vector space always a subspace of some vector space other than itself?
I think: A vector space may not be a subspace of some other vector space. For example: R^3 is a vector space, but it is not a subspace of any other vector space, it is a subspace to itself only. Not True, because
R^3 := {{a,b,c}| a, b, c are real numbers}.
We can defined another set
M := {{a,b,c}| a, b, c are complex numbers},
thus it can be shown that R^3 proper subset of M , and since (i think) M is a vector space, so after all R^3 is a subspace of some other vector space.
Now, is M a subspace of some other vector space?
In general, maybe we can always concoct a vector space V, so that the given vector space is a subset of V, thus a subspace of V.
To Do
Prove: Let A, M, N be matricies. Show that A M + A N==A (M + N).
Coordinate permutation
Coordinate permutation
What kind of structural change occur to column vectors in a matrix during the process of row operation? Perhaps write a Mathematica program illustrating this for 2D and 3D vectors.
1998/03/19.
Suppose we have a point with coordinates {a,b,c}. Now there are six permutations of its coordinate. If we connect all six points to each other, what kind of shape will it form? Especially consider a moving point. The problem can be generalized to higher dimesions.
I thought of it when studying linear algebra, on the paragraph that says "row operations do not change the linear dependence of the original's column vectors".
Solution
Some experiments with Mathematica graphics shows that they are in general a six sided regular polygon lying on a plane, and the polygon has symmetry of that an equiangular triangle.
After thinking, here's my conclusion:
In the 2D analogous problem, the line x==y acts like a mirror. Similarly, the 3D problem have 3 planes that are mirrors. Each plane is the symmetric plane between any two axes. If a point does not lie in one of these planes, then it will be reflected and results 6 points. The 6 points form a hexagon centered on the line x==y==z and orthogonal to it, and it has symmetry of that an equiangular triangle. If we start with two or more points in 3D, then I imagine the result shape would be a prism-shaped in general, with both ends that of a hexagon. So it isn't very interesting. Before this, I thought the answer is some projection of higher dimension objects.


Geometry flavored questions
characteristic of sense-reversing mapping
Given A.x, how do we know that this mapping reverse sense?
A: probably by comparing a oriented triangle and its image.
characteristics of one-to-one mapping
Suppose we have a non-linear continuous mapping from R^n to R^m, with domain equal to R^n.
How can we tell whether this mapping is one-to-one?
geometric view of linear mapping that has maximum number of eigenvalues
Suppose A is an n by n square matrix.
Conjecture: A has maximum of n eigen values.
Conjecture: There exist an n by n matrix A with n eigen values, for any positive integer n > 1.
Question:
Suppose A is a matrix for a linear mapping from R^2 to R^2, with two eigenvalues. I am unable to see intuitively the geometry aspect of such mapping.
If A is an n by n matrix with n eigen values. This means that the transformation has n lines that act like fixedpoints. Take n=2 case. For example, the matrix {{3,-2},{1,0}} has two independent eigen vectors {{1,1},{2,1}} and they are not orthogonal.
Answer: For the 2D case, view it as parallel projection of two planes in 3D. Similarly, higher dimension problem can be visualized using projection.


Typesetting Palette
