Problem of the Big O Notation for Leetcode
problem of the big O notation for algorithmic efficiency
- Say, the problem is writing a factorial function. Now, many math langs has factorial builtin, e.g WolframLang, Matlab etc. Now, suppose we have 2 solutions in the same lang, one is builtin function factorial, the other is myFactorial user-implemented function. Now, What is the algorithmic efficiency of each solution?
- the gist of the question is, what is the atomic unit of algorithmic efficiency of the n in O(n) notation?
- now, if u say, that using a builtin function factorial to compute factorial is O(1), well that's kinda silly, because in comp sci, the algorithmic efficiency of factorial is O(n), almost by definition.
- i always have some issue with the O notation. Namely, what operation we consider as one unit, when we say some algorithm is O(n).
- i think i know the answer.
- basically, O notation is a notion in theoretical comp sci . the unit, in the O(n), is an operation that completes one task of the input.
- So this means, when we use a O notation in a actual programing lang, let's say 2 functions, f1, f2, of the same lang solving the same problem, in a comp sci sense, they both O(n), but in actual real world sense, say, the operation of the compiled assembily code, one may be twice as much operation than the other.
- this create a major problem using O notation concept to compare real world code efficiency.
- for example, say in python, we could have two solution, f1 and f2, both are O(n) to a problem, but, f2 may actually ALWAYS twice as slow.
- in the SAME language!!
- and if we compare solution of two diff langs, things get more wild.
- so in summary, the O notation, we must remember, is a theoretical computer science concept, but in real life coding, it's very misleading.
- yes good point. if we use elisp, the dictionary can be implemented either by a real elisp hashtable, or by elisp's association list. Both solution, would be O(n), but the latter, is always proportionally slower when string length is beyond 10. e.g. when the string length is say 10000, the solution using alist would be super slow. like 10000 times slower, than the same O(n) solution but using hashmap.
- i think i have a conclusion. It is extremely misleading to mostly wrong, to use the algorithmic efficiency big O notation, to measure, the algorithmic efficiency of actual programing code.
- will read wikip later in detail to verify
ok. wikip clarified it. excellent.
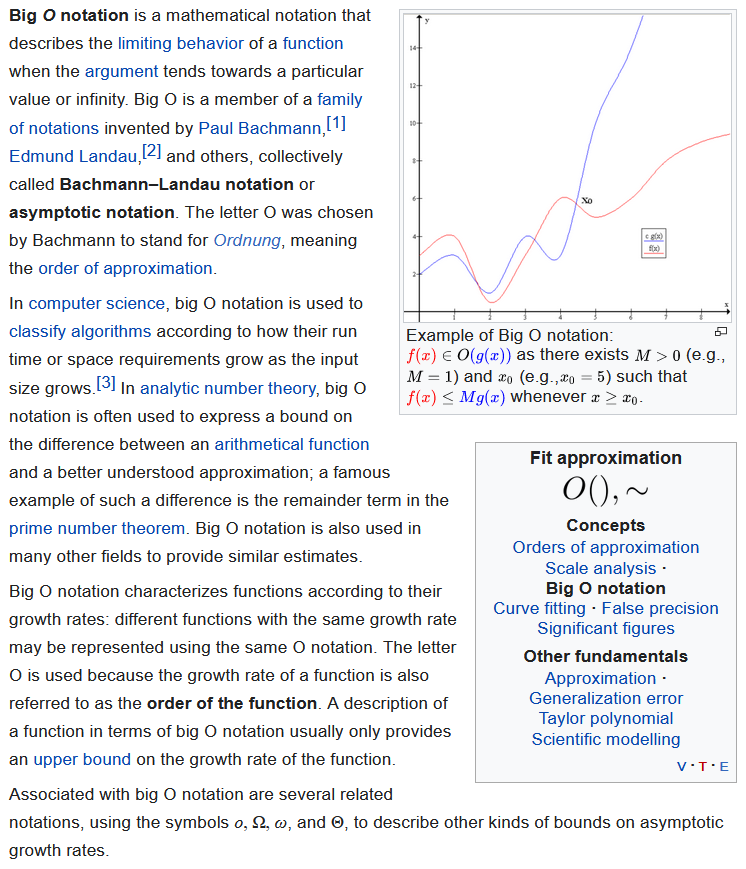
namely, the big O notation, is a measure of growth rate. therefore, obviously, 2 algorithm of the same big O, still may mean, one is always 10 times slower than the other.
- more specifically, when u measure the growth rate of a function, the base unit is whatever it takes for this particular function to complete input of length 1.
- so if we have 2 function f1 and f2, the f2 can always be twice as slow than f1, yet both be O(n)
- so if we have 2 function f1 and f2, the f2 can always be twice as slow than f1, yet both be O(n). because, that's each's
- GROWTH RATE
- this also just means, when we do leetcode exercise, it's almost useless, to use the big O notation for comparing efficiency of solutions.
- in our factorial example, the solution using the builtin function, would be O(1).
- lets say another example.
- The factoring of a number under one thousand.
- lets say we have 2 solution, one uses table lookup, where the code actually contains a hash table hardcoded of all results for number under 1k.
- Another solution uses a builtin function such as FactorInteger of WolframLang.
Unit Cost Operation
