Object Oriented Programing Jargons and Complexities (Explained as Functional Programing)
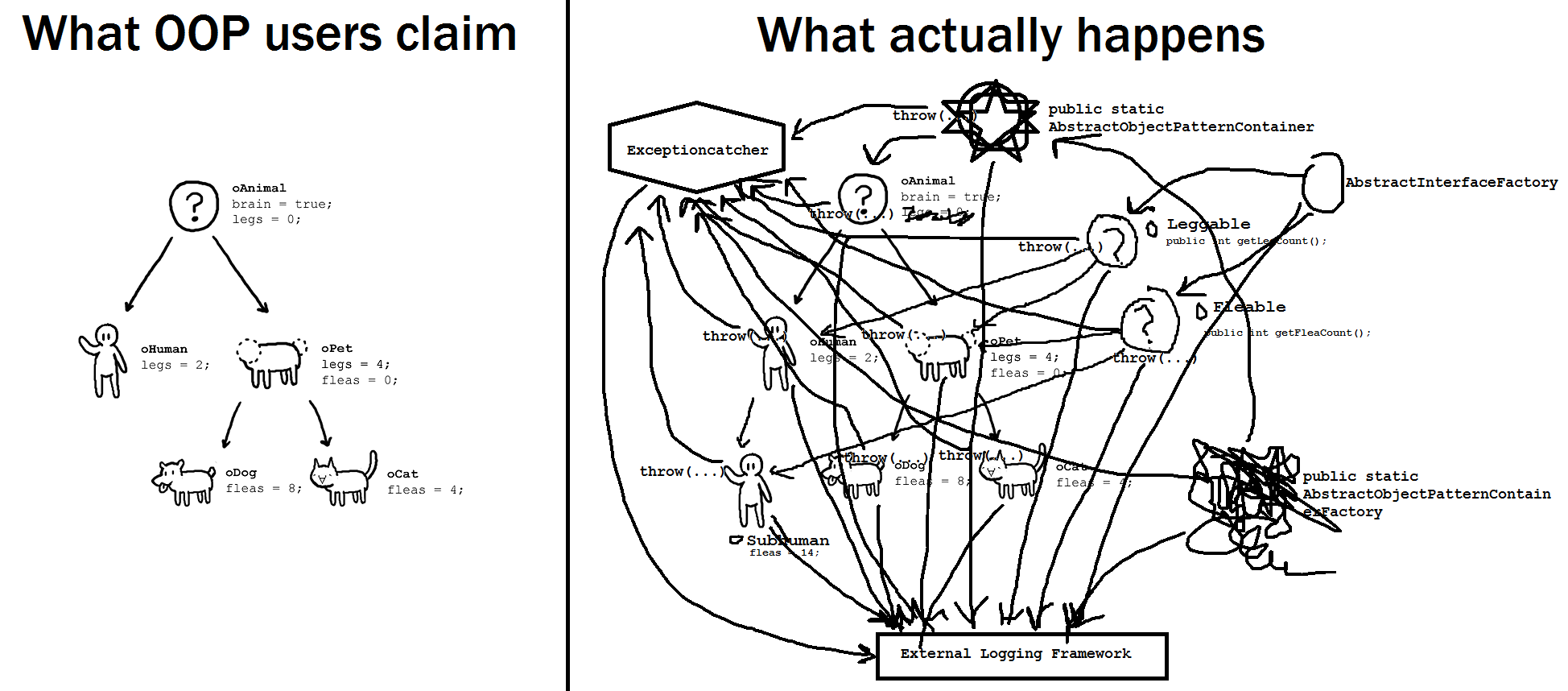
This article explains the jargons and complexities of the Object Oriented Programing (OOP) paradigm, in terms of basic concept of functions, using Java as example.
Classes, Methods, Objects
In computer languages, often a function definition looks like this:
subroutine f (x1, x2, …) {
variables …
do this or that
}
In some languages, it is not uncommon to define functions inside a function. For example:
subroutine f (x1, x2, …) {
variables…
subroutine f1 (x1…) {…}
subroutine f2 (x1…) {…}
}
Often these f1 f2 inner functions are used inside f, and are not relevant outside of f. Such power of the language gradually developed into a style of programing. For example:
subroutine a_surface () {
coordinatesList = …;
subroutine translate (distance) {…}
subroutine rotate (angle) {…}
}
Such a style is that the a_surface is no longer viewed as a function. But instead, a boxed set of functions, centered around a piece of data. And, all functions for manipulating this piece of data are all embodied in this function. For example:
subroutine a_surface (arg) {
coordinatesList = …
subroutine translate (distance) {set coordinatesList to translated version}
subroutine rotate (angle) {set coordinatesList to rotated version}
subroutine return () {return coordinatesList}
if (no arg) {do nothing}
else { apply arg to coordinatesList }
}
In this way, one uses a_surface as a piece of data that are bundled with its own set of functions:
mySurface = a_surface // assign subroutine to a variable mySurface(rotate(angle)) // now the surface data has been rotated mySurface(translate(distance)) // now it's translated newSurface = mySurface(return())
So now, a_surface is no longer viewed as a subroutine, but a boxed set of things centered around a piece of data. All functions that work on the data are included in the boxed set. This paradigm possible in functional languages has refined so much so that it spread to other groups and became known as Object Oriented Programing, and complete languages with new syntax catered to such scheme emerged.
In such languages, instead of writing them like this:
mySurface = a_surface; mySurface(rotate(angle));
the syntax is changed to this, for example:
mySurface = new a_surface(); mySurface.rotate(angle);
In such languages, the super subroutine a_surface is no longer called a function or subroutine. It is now called a Class. And now the variable holding the function “mySurface” is now called a Object. Subroutines inside the function a_surface are no longer called inner-subroutines. They are called Methods. The act of assigning a super-subroutine to a variable is called instantiation.
This style of programing and language has become so fanatical that in such dedicated languages like Java, everything in the language are Classes. One can no longer just define a variable or subroutine. Instead, one defines these super-subroutines (classes) that has inner-subroutines (methods). Every line of code are now inside such super-subroutine. And one assigns subroutines to variables inside other subroutines to create objects. And one calls inner-subroutines (methods) thru these “object” variables to manipulate the data defined in the super-subroutine. In this fashion, even basic primitives like numbers, strings, and lists are no longer atomic entities. They are now subroutines with inner-subroutines.
For example, in Java, a string is a class String. And inside the class String, there are Methods to manipulate strings, such as finding the number of chars, or extracting parts of the string. This can get very complicated.
So, a simple code like this in normal languages:
# ruby a = "a string"; b = "another one"; c = a + b; print c;
or in lisp style:
;; emacs lisp (setq a "a string") (setq b "another one") (setq c (concat a b)) (print c)
becomes in Java:
public class Test { public static void main(String[] args) { String a = new String("a string"); String b = new String("another one"); StringBuffer c = new StringBuffer(40); c.append(a); c.append(b); System.out.println(c.toString()); } }
Here, the new String creates a String object. The new StringBuffer(40) creates the changeable string object StringBuffer, with room for 40 chars. “append” is a method of StringBuffer. It is used to join two Strings.
Notice the syntax c.append(a), which we can view it as calling a inner-subroutine “append”, on a super-subroutine that has been assigned to c, where, the inner-subroutine modifies the inner data by appending the value of “a” to it.
And in the above Java example, StringBuffer class has another method toString() used to convert this into a String Class, necessary because System.out.println's parameter requires a String type, not StringBuffer.
For a example of the complexity of classes and methods, see the Java documentation for the StringBuffer class at
http://java.sun.com/j2se/1.4.2/docs/api/java/lang/StringBuffer.html
(local copy
StringBuffer (Java 2 Platform SE v1.4.1)
)
In the same way, numbers in Java have become a formalization of many classes: Double, Float, Integer, Long… and each has a collection of “methods” to operate or convert from one to the other.
Instead of
aNumber = 3; print aNumber^2;
In Java the programer needs to master the ins and outs of the several number classes, and decide which one to use. (and if a program later needs to change from one type of number to another, it is often cumbersome.)
This Object Oriented Programing style and dedicated languages (such as C++, Java) have become a fad like wild fire among the programing mass of ignoramuses in the industry. Partly because of the data-centric new perspective, partly because the novelty and mysticism of new syntax and jargonization.
It is especially hyped by the opportunist Sun Microsystems with the inception of Java, internet, and web application boom starting around 1995. At those times, OOP (and Java) were thought to revolutionize the industry and solve all software engineering problems, in particular by certain “reuse of components” concept that was thought to come with OOP. (I will cover the “reuse” issue in the inheritance section later.)
As part of this new syntax and purity, where everything in a program is of Classes and Objects and Methods, many complex issues and concept have arisen in OOP from both the OOP language machinery as well as a software engineering practice.
We now know that the jargon “Class” is originally and effectively just a boxed set of data and subroutines, all defined inside a subroutine. And the jargon “Object” is just a variable with value that is this super-subroutine. And the inner-subroutines are what's called “Methods”.
The Rise of “Static” vs “Instance” Variables
In a normal programing language, variables inside functions are used by the function, called local variables.
In OOP paradigm, as we've seen, super-subroutines (classes) are assigned to variables (instantiation), and the inner-subroutines (methods) are called thru the variables (objects).
Because of this mechanism, what's once known as local variables (class variables) can now also be accessed thru the assigned variable (object) by design.
In OOP parlance, a class's variables can be accessed thru the object reference, such as in myObject.data=4.
For example:
mySurface = new a_surface();
mySurface.coordinatesList={…} // assign initial coordinates
However, sometimes a programmer only needs a collection of variables. For example, a list of colors:
black = "#000000"; gray = "#808080"; green = "#008000";
In pure OOP, data as these now come with a subroutine (class) wrapper:
class listOfColors() {
black = "#000000";
gray = "#808080";
green = "#008000";
}
Now to access these values, normally one needs to assign this subroutine (class) to a variable (instantiation) as to create a object:
myColors = new listOfColors(); // instantiation! (creating a “object”) newColor = myColors.black;
As a workaround of this extraneous step is the birth of the concept of “static” variables. (with the keyword “static” in Java) When a variable is declared static, that variable can be accessed without needing to instantiate its class. Example:
class listOfColors() {
static black = "#000000";
static gray = "#808080";
static green = "#008000";
}
newColor = listOfColors.black; // no instantiation required
The issue of staticality is also applicable to inner-subroutines (methods). For example, if you are writing a collection of math functions such as Sine, Cosine, Tangent… etc, you don't really want to require users to create a instance before they can call Sine. Example:
class mathFunctions() {
static sin (x) {…}; // a static method
…
}
print mathFunctions.sin(1); // no need to create object before use
The non-static variant of variables and methods are called instance variables or instance methods, or collectively “instance members”. Note that static members and instance members are very different. With static members, variables and methods can be called without creating a object. But more subtly, for a static variable, there is just one copy of the variable; for instance variables, each object maintains its own copy of the variable. A class can declare just some variables static. So, when multiple objects are created from the class, some variables will share values while others having independent copies. For example:
class a_surface() {
static pi; // a static variable
coordinatesList; // a instance variable
…
};
a_surface.pi=3.1415926; // assign value of pi for all a_surface objects
mySurface1 = new a_surface();
mySurface1.coordinatesList={…} // assign coordinates to one a_surface object
mySurface2 = new a_surface();
mySurface2.coordinatesList={…} // assign coordinates to another a_surface object
The issues of static versus instance members, is one complexity arising out of OOP.
The Rise of “Constructors” and “Accessors”
A instantiation, is when a variable is assigned a super-subroutine (class). A variable assigned such a super-subroutine is now called a instance of a class or a object.
In OOP practice, certain inner-subroutines (methods) have developed into specialized purposes. A inner-subroutine that is automatically called by the language when the super-subroutine is assigned to a variable (instantiation), is called a constructor or initializer. These specialized inner-subroutines are sometimes given a special status in the language. For example in Java the language, constructors have different semantics than methods. (in Java, the constructor “method” cannot have return type, and must have the same name as the class)
In OOP, it has developed into a practice that in general the data inside super-subroutines are supposed to be changed only by the super-subroutine's inner-subroutines, as opposed to by reference thru the super-subroutine.
(In OOP parlance: class's variables are supposed to be accessed/changed only by the class's methods.) Though this practice is not universal or absolute.
Inner-subroutines that change or return the value of variables are called accessors.
For example, in Java, a string class's method length() is a accessor.
Because constructors are usually treated as a special method at the language level, its concept and linguistic issues is a OOP machinery complexity, while the Accessor concept is a OOP engineering complexity.
(See this tutorial on the complexities of Java's constructor, involving the default constructor, declaration of return type, and inheritance issues. [see Java: Constructor] )
The Rise of “Access Specifiers” (or, the Scoping Complexity of OOP)
In programing, a variable has a scope — meaning where the variable can be seen. Normally, there are two basic models: dynamically scoped and lexically scoped. Dynamic scoping is basically a time based system, while lexical scoping is text based (like “what you see is what you get”). For example, consider the following code:
subroutine f() {return y}
{y=3; print f();}
In dynamic scoping, the printed result is 3, because during evaluation of the block all values of y is set to 3. In lexical scoping, a undefined “y” is printed because the two “y” in the code are considered different because they are in separate blocks of curly brackets. With regards to language implementation, Dynamic Scoping is the no-brainer of the two, and is the model used in earlier languages. Most of the time, lexical scoping is more natural and desired because it corresponds to the code's nesting brackets.
Scoping is also applicable to names of subroutines. That is, where subroutines can be seen. A subroutine's scope is usually at the level of source file (as a concept of a namespace), because subroutines are often used in the top level of a source file, as opposed to inside a code block like variables.
In general, the complexity of scoping is really just how deeply nested a name appears. For example see in the following code:
name1; // top level names. Usually subroutines, or global variables.
{
name2 // second level names. Usually variables inside subroutines.
{
name3 // deeper level names. Less often used in structured programing.
// often used in nested loops
}
}
If a programing language uses only one single file of commands in sequence as in the early languages such as BASIC, there would be no scoping concept. The whole program is of one single scope. This is before structured programing was introduced in the 1970s. Here's a example of early BASIC in the 1970s:
10 INPUT "What is your name: ", U$ 20 PRINT "Hello "; U$ 30 INPUT "How many stars do you want: ", N 40 S$ = "" 50 FOR I = 1 TO N 60 S$ = S$ + "*" 70 NEXT I 80 PRINT S$ 90 INPUT "Do you want more stars? ", A$ 100 IF LEN(A$) = 0 THEN GOTO 90 110 A$ = LEFT$(A$, 1) 120 IF A$ = "Y" OR A$ = "y" THEN GOTO 30 130 PRINT "Goodbye "; U$ 140 END
OOP has created a immense scoping complexity because its mode of computing is calling nested subroutines (methods) inside subroutines (classes).
In OOP, variables inside subroutines (class variables) can also be accessed thru a reference the subroutine is assigned to (that is, a object). In OOP parlance: a variable in a class is lexically scoped, while the same variable when the class is instantiated (a object) is dynamically scoped. In other words, OOP created a new entity “variable thru reference” that comes with its own scoping issue. For example:
class a_surface() {
coordinates={…}; // a variable
…
}
class main {
mySurface = new a_surface();
mySurface.coordinates = {…}; // accessing the “same” variable
}
In the above code, the variable “coordinates” appears in two places. Once as defined inside a_surface, and once as a instantiated version of a_surface (a object). The variable as thru the object reference apparently has a entirely different scoping issue than the same variable inside the subroutine (class) definition. The question for OOP language designers is: what should the scope be for variables referred thru objects? Lexically within the class the object is created? Lexically within the class the variable is defined?? globally? (and what about inherited classes? (we will cover OOP inheritance later))
As we've seen, methods are just inner-subroutines, and creating objects to call methods is OOP's paradigm. In this way, names at the second-level programing structure often associated with variables (and inner-subroutines), is now brought to the forefront. That is: the scoping of subroutines are raised to a level of complexity as the scoping of variables. (they are now both in the 2nd level of names (or deeper).)
Further, in a class definition, variables are lexically scoped. But the ability for a object to refer/change a class variable is essentially a model of dynamic scope. Thus, OOP created a complexity of mixing these 2 scoping models.
All in all, the scoping complexities of OOP as applied to different OOP entities (classes, class variables, class's methods, object variables and methods) is manifested as access specifiers in Java. In Java, access specifiers are keywords private, protected, public, used to declare the scope of a entity. Together with a default scope of no-declaration, they create 4 types of scope, and each of these keywords has entirely different effects depending whether they are used on a variable, a method, a constructor, or a class.
On the surface, these access specifiers seems to be created for good engineering practices, giving the programer more power in controlling misuse of entities. Mathematically, these access specifiers is necessary due to the fact of computing model of:
- Assigning subroutine to variable (instantiation)
- Calling subroutine with argument of subroutine name (calling method)
- Calling subroutine with argument of variable name (accessing object variable via object)
- Calling subroutine with argument of variable name declared static (accessing class variable via class)
See this tutorial of Java's access specifiers for detail:
The Rise of “Inheritance”
In well-thought-out languages, functions can have inner functions, as well as taking other functions as input and return function as output. This is a result of design principle of consistency and simplicity. Here are some examples illustrating the use of such facilities.
Function Returning a Function
subroutine ExponentialFunctionGenerator(n) {
return subroutine (x) {return x^n};
}
In the above example, the subroutine ExponentialFunctionGenerator returns a function, which takes a argument and raise it to nth power. It can be used like this:
print ExponentialFunctionGenerator(2)(5) // prints 25
The above returns 25, because ExponentialFunctionGenerator(2) returns the function x^2, and this function is given the argument 5, therefore arriving at 5^2 or 25.
Function Taking a Function as Input
subroutine fixedPoint(f,x) {
temp=x;
while (f(temp) != temp) {
temp=f(temp);
}
return temp;
}
In the above example, fixedPoint takes two arguments f and x, where f is taken to be a function.
It applies f to x, and apply f to that result, and apply f to that result again, and again, until the result doesn't change.
i.e., it computes f[f[f[…f[x]…]]].
FixedPoint is a math notion.
For example, it can be employed to implement Newton's Method of solutions to equations as well as many problems involving iteration or recursion.
FixedPoint may have a optional third parameter of a true/false function fixedPoint(func, arg, predicate) as a alternative way to determine when the nesting should stop.
In this form, it is equivalent to the “while loop” or “for loop” in procedural languages.
Function Composition
If we apply two functions, one after another, as in g[f[x]], then we can think of it as one single function that is a combined f and g.
In math notation, it is often denoted as (g◦f).
For example, g[f[x]]→y is the same as (g◦f)[x]→y.
Here is a pseudo-code example of defining a function composition.
subroutine composition(f,g,h) {
return subroutine {f(g(h))};
}
In our example given above, the function “composition” takes any number of arguments, and returns a single function of their composition.
Function vs Function's Name
When we define a subroutine, for example:
subroutine f(n) {return n*n}
the function is power of two, but the function is named f. Note here that a function and its name are two different concepts. In well-thought-out languages, defining a function and naming a function are not made inseparable. In such languages, they often have a keyword that is used to define functions. The keyword is often named “lambda” or just “function” . Then, one can assign it a name if one so wishes. This separation of concepts made many of the linguistic power in the above examples possible. Example:
lambda (n) {return n^2;} // a function
(lambda (n) {return n^2;})(5) // a function applied to 5.
f = lambda (n) {return n^2;} // a function is defined and named (by assigning it to a variable)
f(5) // a function applied to 5.
lambda (g) {return lambda {g(f)};} // a function composition of g and f.
Concept of Inheritance
The above facilities may seem exotic to industrial programers, but it is in this milieu of linguistic qualities the object oriented paradigm arose, where it employs facilities of defining inner function (method), assigning function to variable (instantiation), function taking function as inputs (calling method thru object), and application of functions to expressions (applying methods to data in a class).
The data-bundled-with-functions paradigm finds fitting applications to some problems. With the advent of such Object-Oriented practice, certain new ideas emerged. One of great consequence is the idea of inheritance.
In OOP practice, computations are centered around data as entities of self-contained boxed sets (classes). Thus, frequently a programer needs slightly different boxed sets than previously defined. Copy and Pasting existing code to define new boxed sets quickly made it unmanageable. (a messy set of classes). With powerful linguistic environment and habituation, one began to write these new boxed-subroutines (classes) by extending old subroutines (classes) in such a way that the new subroutine contains all variables and subroutines of a base subroutine without any of the old code appearing in the body of the subroutine. Here is a pseudo-code illustration:
g = ext(f) {
new variables …
new inner-subroutines …
return a subroutine that also contains all stuff in subroutine f
}
Here, “ext” is a function that takes a argument f, and returns a new function such that this new function contains all the boxed-set things in f, but added its own. This new boxed-set subroutine is given a name g.
In OOP parlance, this is the birth of inheritance. Here, g inherited from that of f. f is called the base class of g, and g is the derived class of f. (base class is also known as superclass, and derived class is also known as subclass).
In functional terms, inheritance mechanism is a function E that takes another function f as input and returns a new function g as output, such that g contained all enclosed members of f with new ones defined in E. In pure OOP languages such as Java, the function E is exhibited as a keyword “extends”. For example, the above code in Java is like this:
class g extends f {
new variables …
new inner-subroutines …
}
Here is the same example in Python, where inheritance takes the form of a class definition with a parameter:
class g(f): new variables … new inner-subroutines …
Data are the quintessence in computation. Because in OOP all data are embodied in classes, and wrapping a class to each and every variety of data is unmanageable, inheritance became the central means to manage data.
The Rise of Class Hierarchy
Because of psychological push for purity, in Java there are no longer plain subroutines. Everything is a method of some class. Standard functions like opening a file, square root a number, “for” loop constructs, “if … else” branching statements, or simple arithmetic operations… must now somehow become a method of some class. In this way, coupled with the all-important need to manage data with inheritance, the OOP Class Hierarchy is born.
Basic data types such as now the various classes of numbers, are now grouped into a Number class hierarchy, each class having their own set of methods. The characters, string or other data types, are lumped into one hierarchy class of data types. Many types of lists (variously known as arrays, vectors, lists, hashes, etc), are lumped into one hierarchy, with each Class node having its own set of methods as appropriate. Math functions, are lumped into a math class hierarchy.
Now suppose the plus operation +, where does it go? Should it become a method of the various classes under the Number heading, or should it be a method of the Math class set? Each language deals with these issues differently.
As a example, see this page for the hierarchy of Java's core language classes:
http://java.sun.com/j2se/1.4.2/docs/api/java/lang/package-tree.html
(local copy:
java.lang Class Hierarchy (Java 2 Platform SE v1.4.1)
)
OOP being inherently complex exacerbated by marketing propaganda, and the inheritance and hierarchy concept is so entangled in OOP; There is a tendency that any computing entities having a tree-structure is erroneously termed Object-Oriented. (there are now also so-called Object-Oriented databases that ride the fad of “all data are trees”. (For organizing computing entities, a tree is richer than a flat sequence, but poorer than a general relational structure, in which a tree is merely one particular type of relation.))
A Example of Hierarchy Pain
The “everything is a class on a tree” gets to be a pain quickly. Here's a example of reading and writing to a file. In normal languages,
# perl open(f,"</Users/joe/t1.txt") or die "error opening file f: $!"; open(f2,">/Users/joe/t2.txt") or die "error opening file f2: $!"; while ($line = <f>) {print f2 $line;} close(f) or die "error: $!"; close(f2) or die "error: $!";
# python f=open("/Users/joe/t1.txt",'r') f2=open("/Users/joe/t2.txt",'w') for line in f: f2.write(line) f.close() f2.close()
In order to read or write a file in Java, one needs not only create a input file object and output file object, but also a FileReader object to read it and FileWriter object to write to it. Here's the Java code:
import java.io.*; public class RawFile { public static void main(String[] args) throws IOException { File f = new File("/Users/joe/t1.txt"); File f2 = new File("/Users/joe/t2.txt"); FileReader in = new FileReader(f); FileWriter out = new FileWriter(f2); int c; while ((c = in.read()) != -1) out.write(c); in.close(); out.close(); } }
See this page for the complexity of the IO tree
http://java.sun.com/j2se/1.4.2/docs/api/java/io/package-tree.html
(local copy
java.io Class Hierarchy (Java 2 Platform SE v1.4.1)
)
See this page for the documentation of the File class itself.
http://java.sun.com/j2se/1.4.2/docs/api/java/io/File.html
(local copy
File (Java 2 Platform SE v1.4.1)
)
The following are written much later, that i never actually finished writing this article. Someday, i'll rewrite them into this article as a coherent whole.
The Rise and Mutation of “Interface”
See:
The Rise of Abstract Class and Abstract Methods
See: Java: abstract (keyword) .
The Rise of Iterators and Enumerators
comp lang: Iterator, Enumerator, Abstraction Went Wrong (2016)
See also:
- Iterators: Signs of Weakness in Object-Oriented Languages
- By Henry G Baker.
http://home.pipeline.com/~hbaker1/Iterator.html- (local copy Iterators_Signs_of_Weakness_in_Object_Oriented_Languages__Henry_G_Baker__1992.txt )
A Examination of Code Re-Use
The Jargon Polymorphism
- Jargon: Polymorphism and Dispatch (2015)
- Object Oriented Programing Dot Notation Ambiguity. Data Before Dot or After Dot (2013)
misc
see:
- Goodbye, Object Oriented Programming
- By Charles Scalfani.
- https://medium.com/@cscalfani/goodbye-object-oriented-programming-a59cda4c0e53#.kh01ewep9
Object Oriented Programing
- Object Oriented Programing Jargons and Complexities (Explained as Functional Programing)
- History of Object Oriented Programing, by Casey Muratori (2025)
- Object Oriented Programing, Origin of Inheritance (Simula)
- Alan Kay on Object Oriented Programing
- comp lang: Iterator, Enumerator, Abstraction Went Wrong (2016)
- Iterators: Signs of Weakness in Object-Oriented Languages (By Henry G Baker, 1992)
- Jargon: Polymorphism and Dispatch (2015)
- Meaning of Object in Computer Languages