pseudo random number
random number generator
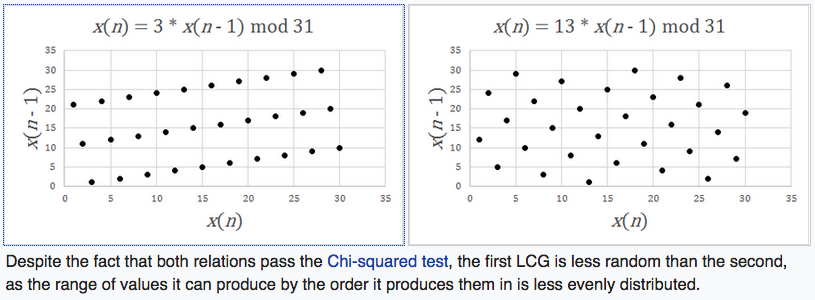
one old, popular pseudo random number generator algorithm is called Linear congruential generator. It works like this:
x[2]:= mod(A*x[1]+C, M)
, where A C M are carefully chosen numbers.
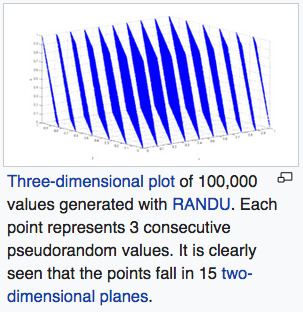
lol. this is graph of “Spectral test” on random number generator algorithm called Linear Congruential Generator (LCG). One major problem of LGC is that, when consecutive terms are taken as n-tuple and plotted, they form n-dimentional planes. e.g. when n=3, the points lie on parallel planes.
Spectral test
The spectral test is a statistical test for the quality of a class of pseudorandom number generators (PRNGs), the linear congruential generators (LCGs).[1] LCGs have a property that when plotted in 2 or more dimensions, lines or hyperplanes will form, on which all possible outputs can be found. The spectral test compares the distance between these planes; the further apart they are, the worse the generator is.[2] As this test is devised to study the lattice structures of LCGs, it can not be applied to other families of PRNGs.
According to Donald Knuth,[3] this is by far the most powerful test known, because it can fail LCGs which pass most statistical tests. The IBM subroutine RANDU[4][5] LCG fails in this test for 3 dimensions and above.
2018-12-25 Spectral test
linear congruential generator
A linear congruential generator (LCG) is an algorithm that yields a sequence of pseudo–randomized numbers calculated with a discontinuous piecewise linear equation. The method represents one of the oldest and best–known pseudorandom number generator algorithms.[1] The theory behind them is relatively easy to understand, and they are easily implemented and fast, especially on computer hardware which can provide modulo arithmetic by storage–bit truncation.
The generator is defined by recurrence relation:
x[n]:= mod(A*x[n-1]+C, M)2018-12-25 Linear congruential generator
Statistical randomness
one good article to read is Statistical Randomness, to get a sense how we don't have a general definition of “random sequence”. you see that they are many tests that's all kinda arbitrary.
A numeric sequence is said to be statistically random when it contains no recognizable patterns or regularities; sequences such as the results of an ideal dice roll or the digits of π exhibit statistical randomness.[1]
Statistical randomness does not necessarily imply "true" randomness, i.e., objective unpredictability. Pseudorandomness is sufficient for many uses, such as statistics, hence the name statistical randomness.
Global randomness and local randomness are different. Most philosophical conceptions of randomness are global — because they are based on the idea that “in the long run” a sequence looks truly random, even if certain sub-sequences would not look random. In a “truly” random sequence of numbers of sufficient length, for example, it is probable there would be long sequences of nothing but repeating numbers, though on the whole the sequence might be random. Local randomness refers to the idea that there can be minimum sequence lengths in which random distributions are approximated. Long stretches of the same numbers, even those generated by “truly” random processes, would diminish the “local randomness” of a sample (it might only be locally random for sequences of 10,000 numbers; taking sequences of less than 1,000 might not appear random at all, for example).
A sequence exhibiting a pattern is not thereby proved not statistically random. According to principles of Ramsey theory, sufficiently large objects must necessarily contain a given substructure (“complete disorder is impossible”).
2018-12-25 Statistical randomness
dice
they have metal ones now.

why metal? is it just cool factor or something else?
apparently, lots something else. lots of these Dungeon And Dragon dice are not well made, and have strong bias.

- https://youtu.be/VI3N4Qg-JZM
- How to check the balance of your D20
- by Daniel Fisher
- Published on Jun 9, 2015


- https://youtu.be/UdA5ydENTHY
- Automatic Die Roller with Camera
- by markfickett
- Published on Nov 28, 2015
- http://www.markfickett.com/stuff/artPage.php?id=389
more dice testing. http://www.1000d4.com/2013/02/14/how-true-are-your-d20s/
more exotic math dices you can buy. http://thedicelab.com/
The meaning of “random number”, is one great representation of the mysteries of math. we are unable define it mathematically in general. The closest we have, is Kolmogorov's zen-like definition. It says, a sequence is random if no shorter program can describe it.
The mathematical theory of probability arose from attempts to formulate mathematical descriptions of chance events, originally in the context of gambling, but later in connection with physics. Statistics is used to infer the underlying probability distribution of a collection of empirical observations. For the purposes of simulation, it is necessary to have a large supply of random numbers or means to generate them on demand.
Algorithmic information theory studies, among other topics, what constitutes a random sequence. The central idea is that a string of bits is random if and only if it is shorter than any computer program that can produce that string (Kolmogorov randomness)—this means that random strings are those that cannot be compressed. Pioneers of this field include Andrey Kolmogorov and his student Per Martin-Löf, Ray Solomonoff, and Gregory Chaitin. For the notion of infinite sequence, one normally uses Per Martin-Löf's definition. That is, an infinite sequence is random if and only if it withstands all recursively enumerable null sets. The other notions of random sequences include (but not limited to): recursive randomness and Schnorr randomness which are based on recursively computable martingales. It was shown by Yongge Wang that these randomness notions are generally different.[11]
Randomness occurs in numbers such as log (2) and pi. The decimal digits of pi constitute an infinite sequence and “never repeat in a cyclical fashion.” Numbers like pi are also considered likely to be normal, which means their digits are random in a certain statistical sense.
Pi certainly seems to behave this way. In the first six billion decimal places of pi, each of the digits from 0 through 9 shows up about six hundred million times. Yet such results, conceivably accidental, do not prove normality even in base 10, much less normality in other number bases.[12]
2018-12-24 from Randomness
and here's article on normal number
In mathematics, a normal number is a real number whose infinite sequence of digits in every positive integer base b[1] is distributed uniformly in the sense that each of the b digit values has the same natural density 1/b, also all possible b2 pairs of digits are equally likely with density b−2, all b3 triplets of digits equally likely with density b−3, etc.
Intuitively this means that no digit, or (finite) combination of digits, occurs more frequently than any other, and this is true whether the number is written in base 10, binary, or any other base. A normal number can be thought of as an infinite sequence of coin flips (binary) or rolls of a die (base 6). Even though there will be sequences such as 10, 100, or more consecutive tails (binary) or fives (base 6) or even 10, 100, or more repetitions of a sequence such as tail-head (two consecutive coin flips) or 6-1 (two consecutive rolls of a die), there will also be equally many of any other sequence of equal length. No digit or sequence is "favored".
While a general proof can be given that almost all real numbers are normal (in the sense that the set of exceptions has Lebesgue measure zero), this proof is not constructive and only very few specific numbers have been shown to be normal. For example, Chaitin's constant is normal (and uncomputable). It is widely believed that the (computable) numbers √2, π, and e are normal, but a proof remains elusive.
2018-12-24 Normal number