Emacs Lisp Doc String Curly Quote Controversy (2015)
Toothpick Syndrome in Emacs Docstring, created by Alan Mackenzie in 2015
here's the misery Alan Mackenzie created.

In 2015, emacs dev mailing list has a flame war about whether elisp doc string should contain the curly quotes as literal unicode characters.
“U+201C: LEFT DOUBLE QUOTATION MARK”“U+201D: RIGHT DOUBLE QUOTATION MARK”
It ends up with thousand or so messages, spanning 4 months.
〔2015-09-09 Artur Malabarba on twitter
Here's some of the evolution of the thread titles:
- Support curved quotes in doc strings. 2015-05-28
- Upcoming loss of usability of Emacs source files and Emacs. 2015-06-15 https://lists.gnu.org/archive/html/emacs-devel/2015-06/msg00202.html
- On the masking of undisplayable characters
- A simple solution to “Upcoming loss of usability ...”
- Escaping quotes in docstrings
- text-quoting-style
- Please stop putting curly quotes into doc strings. 2015-09 https://lists.gnu.org/archive/html/emacs-devel/2015-09/msg00253.html
The Curly Quote Problem
emacs uses this convention to quote functions in docstring:
`something'
this was a 1970's hack, for lacking matching quotes.
it is desired to use a matching quotes such as
“something”
or
‘something’
The discussion begin by changing emacs convention, but some people complained that they do not want non-ascii characters to be in source code, because it is hard to type.
Eventually, it ends up with a complex solution of a conversion layer, so that what you see is not what shown in the actual source code, but also, some simple text such as
'some
in docstring now needs to be written as
\\='some.
this is worse than having no curly quotes at all.
The guy who created the problem is Alan Mackenzie. And it is Richard Stallman, who have not coded for ~15 years, indirectly sealed the fate, due to his fame.
The Great Curly Quote Hero: Paul Eggert
The support for curly quotes and auto rendering of
emacs style quote
e.g.
`something'
to
single curly quotes
e.g.
‘something’
is coded by Eggert.
You can see lots of his coding in emacs git.
One of Eggert's message cited my article.
Re: [Emacs-diffs] master 9ce1d38: Use curved quotes in core elisp diagno
From: Paul Eggert
Subject: Re: [Emacs-diffs] master 9ce1d38: Use curved quotes in core elisp diagnostics
Date: Tue, 18 Aug 2015 10:34:45 -0700
Bastien wrote:
Paul Eggert writes:
Format strings are easier to read and use, particularly by novices, if
characters typically stand for themselves.
Did we ever receive a complaint from a novice about `...' readability?
Most novices don't bother to write bug reports — they don't even know how to write bug reports. But yes, people occasionally gripe about the use of grave accent to quote, and this can hurt Emacs's reputation among people who may not know it better. For example, http://wordyenglish.com/musing/typography.html (2007) says:
"the problem with the GNU is that even today, in 2007, where curly quotes have been widely available in word processors for over a decade (and Unicode have been practical and widely available for at least 5 years...), they are still using plain ASCII hacks. (in general, GNU and the Open Source morons have like a 5 to 10 years lag in adopting technology, for reasons that are inadvertently intentional and or simply incapable)"
And here we are in 2015, with the quote problem still only partly fixed.
Idiot Dmitry Gutov
• Re: [Emacs-diffs] master 9ce1d38: Use curved quotes in core elisp diagno
• From: Dmitry Gutov
• Subject: Re: [Emacs-diffs] master 9ce1d38: Use curved quotes in core elisp diagnostics
• Date: Tue, 18 Aug 2015 23:47:36 +0300
On 08/18/2015 08:34 PM, Paul Eggert wrote:
Most novices don't bother to write bug reports — they don't even know
how to write bug reports.
Bug reports are written by users who are at least a little experienced, sure, but we shouldn't assume that every such user has necessarily become accustomed to Emacs's quirks, and wouldn't call out this problem, if it were a real problem.
But yes, people occasionally gripe about the
use of grave accent to quote, and this can hurt Emacs's reputation among
people who may not know it better. For example,
<http://wordyenglish.com/musing/typography.html> (2007) says:
I sincerely hope the whole effort wasn't kicked off by this Xah Lee's rant. It's pretty shallow. And the author should really "know Emacs better" by now.
"the problem with the GNU is that even today, in 2007, where curly
quotes have been widely available in word processors for over a decade
(and Unicode have been practical and widely available for at least 5
years...), they are still using plain ASCII hacks. (in general, GNU and
the Open Source morons have like a 5 to 10 years lag in adopting
technology, for reasons that are inadvertently intentional and or simply
incapable)"
"morons"... yeah.
And here we are in 2015, with the quote problem still only partly fixed.
One would have to define the "problem" first.
In 2015, the documentation markup languages (Markdown, Asciidoc, etc) support rich content (images, hyperlinks, document structure), and decoupling markup from presentation (usually through rendering into HTML).
Yet here we are, not talking about any big features, and instead discussing using unicode quotes in the markup (which none of the modern markup languages do), because it's "easier" if the markup and presentation are the same. That's a step back, if anything.
https://lists.gnu.org/archive/html/emacs-devel/2015-08/msg00651.html
Why We Should Allow Curly Quote in Source Code
I've read all the reasons against using unicode directly in source code. Most of them are, idiotic.
One simple way to see this is that, in China or Japan, where you have few thousand chars, you use them, without ado.
For Western white men, somehow, there's a sense that ASCII should be the only char used in computer source code. This idea, is held usually by old coders. The millennials, mostly have no problem with NON-ASCII chars. They grew up with it.
here's a nice summary by Stephen J. Turnbull, who was the leader for xemacs.
Stephen J. Turnbull Subject: Re: [Emacs-diffs] master 9ce1d38: Use curved quotes in core elisp diagnostics Date: Wed, 19 Aug 2015 15:31:47 +0900 Óscar Fuentes writes: > Dmitry suggests this, and his comment about modern markup languages > restricting themselves to ASCII is something to think about. Not really. No chicken developed from that egg because there was no chicken to lay the egg in the first place. By and large programmers' environments are deficient in respect of input methods, especially in the U.S., and until a few years ago solid multilingual Unicode environments weren't really available (and still aren't on Windows, if I understand Eli's descriptions correctly). So programmers (who design markup languages) restrict themselves to ASCII-based markup. It's only become reasonable to think about going beyond ASCII in the last 5 years or so (if you want to maintain fairly general appeal). And there's the counterexample of Xe[La]TeX, which in fact developed for Mac, the most complete Unicode implementation available at the time — a single anecdote, but very suggestive IMHO. Emacs is the perfect environment to experiment with *discoverable* *multilingual* input methods. AFAIK, they don't exist yet, *anywhere*. Apple is going backwards, even. Microsoft doesn't have them, either. The proprietary technology is quite good — within the context of monolingual environments (which is where the money is, even in Europe the number of companies where individuals need multilingual environments is limited). But they require effort for neophytes to learn, and are less than useful for "inputting 'exotic' characters." As far as I can tell, there's nothing better out there for free software, either -- we're now on our fourth or fifth generation of new input management frameworks for GNOME and/or KDE, and *still* the most frequent n00b question on the Tokyo Linux Users Group[sic] is "I just upgraded MyDistro and now I can't input Japanese in WhateverOffice". My Chinese students and Buddhist scholar friends all use Macs because it's very easy to switch among input methods (Chinese, Japanese, and Sanskrit are radically different -- it's sort of possible to share an input method between Chinese and Japanese, but it's very painful). But all of these methods are monolingual, and must be learned separately (or "taught", as most "learn" the user's habits, changing priorities in the dictionaries and storing common sequences of words for "predictive translation"). Emacs at least has Quail, giving language flexibility as good or better than Apple, although the input methods themselves are static, so aren't as user-friendly as the proprietary ones that "learn" the users' habits. And (one small step for Emacs, one giant step for mankind) Quail methods are self-documenting (although again discoverability needs to be improved for the purpose of "typing 'exotic' characters"). > I admit that I'm intrigued by your plan about how this change will > initiate an evolution on Emacs input system that will make easier to > type exotic characters (defining "exotic" by "something that it is > infrequent in your daily usage.") By giving people an itch they want to scratch. Most people will just cut'n'paste or add ad hoc keybindings for the characters they need. Some people will do more, and sooner or later one of them will come up with a much better way to do input methods. It's not obvious to me what that will be, and it's probably useless to ask Paul what it will be too. David K pointed out that there are some useful ideas in x-symbol. That might be one place to look. Also, besides input methods, it will likely lead to improvements in other technologies such as searching (adding character classes of "cognates" such as ` and ‘, for example — this is useful for repertoires like Japanese which has about a dozen variants on open parenthesis more or less commonly used in text, as well as a pile of numeral variants used for paragraph numbering, and the like). Those opposed to the change will cry YAGNI, and that's true — if you live in an 8-bit world anyway, you just can't afford that kind of redundancy. But like it or not, the world is now mostly Unicode and that will only increase. Japanese is probably the most perverse character set in existence, but I believe Chinese and Korean also have similar issues of many classes of characters that have redundant functionality, and it shows up in other places (eg, arrows and emoticons). > Maybe describing the specific user-visible improvements that this > change will help to bring into reality would buy you more support. The user-visible improvements have been described and are easily visible to the eye desiring to see them. Tastes just differ here; the people who don't like the change see little to no improvement, and IIUC Drew even considers it a clear step backward aesthetically.
from Stephen J. Turnbull http://lists.gnu.org/archive/html/emacs-devel/2015-08/msg00676.html
What is the problem of using some form of encoding for none ascii chars?
Using encoded form is unreadable when you have lots of them. And it adds complexity of a transformation step.
e.g. in math, → ∑ α etc.
not
→
∑
α
etc in html.
Or worse in TeX escape or
\xhhhh
or
\xhhhhhh
in many langs.
Or consider euro lang. é and other. Basically, when you have several of that in a sentence, using encoded form is not practical. You have unreadability, and complexity of conversion, which easily go wrong, e.g. Encoded/decoded twice.
Imagine, if Spanish people had to write niña by ni&ntilde;a or ni\x00f1a. Or French has to read télé from t&eacute;l&eacute; or t\x00e9l\x00e9. That is what programers who insist on ascii-only source code are asking.
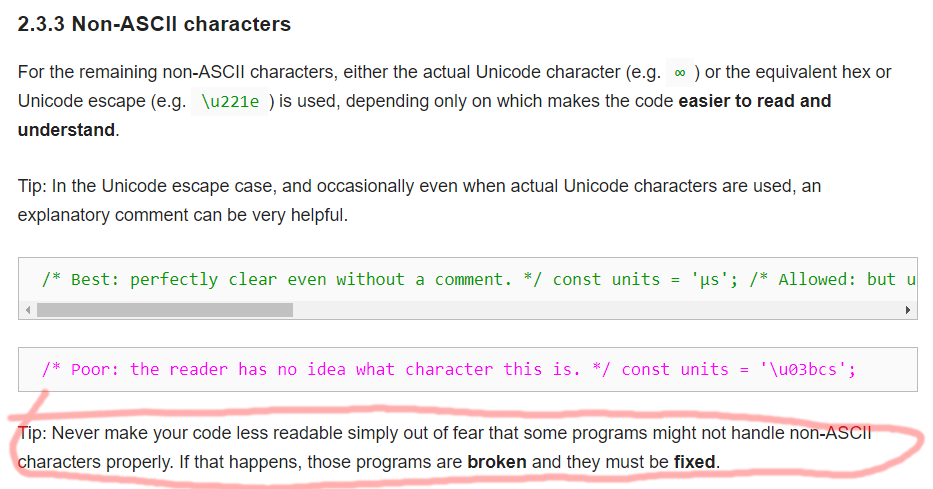
Google Style Guide on Curly Quote in Source Code
Never make your code less readable simply out of fear that some programs might not handle non-ASCII characters properly. If that happens, those programs are broken and they must be fixed.

- https://youtu.be/BouMWCJJ98w?start=857
- Curly Quotes, Unicode, Emacs, and the Crime of RMS
- Xah Talk Show 2021-05-29 Curly Quotes, Unicode, Emacs, and the Crime of RMS
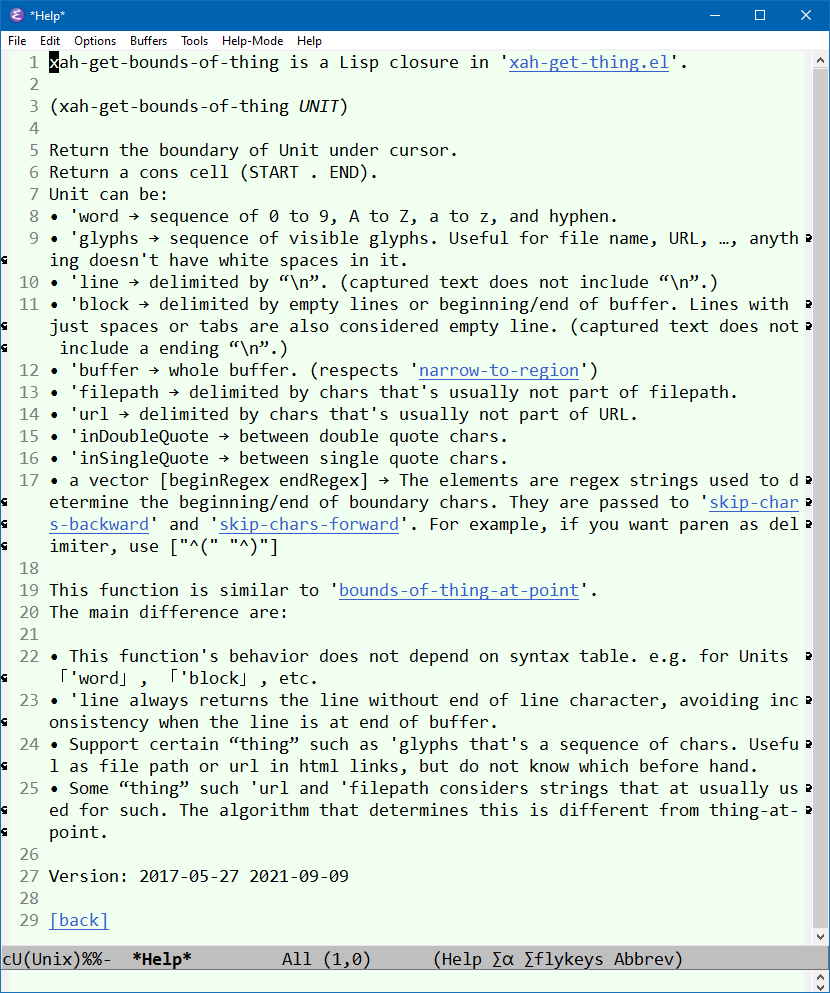
here's how the curly quote complex fuck things up.
before, you can write things literally, in particular, symbol values can be represented as 'symbol, they look as is:
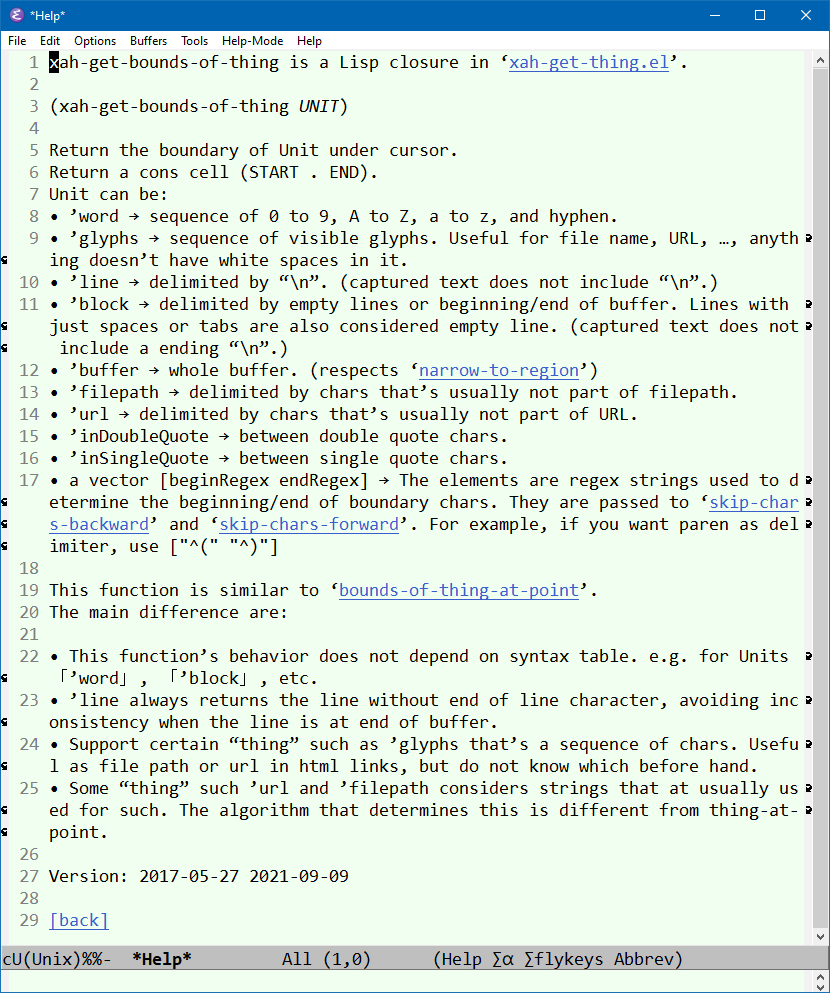
now after the render layer Alan Mackenzie fuckup, it looks like this:
The Fate of Curly Quote in Emacs Docstring and Who to Blame
- It is Alan Mackenzie, who insisted that docstring should be pure ASCII.
- After hundreds of flamewar messages, then, it is Richard Stallman, by a casual remark, sealed the damage.
- Richard Stallman, as far as i know, he has not participated in the discussion.
- Stallman was not a emacs maintainer at the time, and by maintainer agreement, he does not have the authority for final decision on anything none political.
- Maintainer was Stefan Monnier.
From: Richard Stallman Subject: Please stop putting curly quotes into doc strings! Date: Fri, 04 Sep 2015 21:14:42 -0400 Please stop inserting curly quotes into doc strings in Emacs sources. -- Dr Richard Stallman President, Free Software Foundation (gnu.org, fsf.org) Internet Hall-of-Famer (internethalloffame.org) Skype: No way! See stallman.org/skype.html.
Emacs Text Quoting Conversion in Docstring
ASCII Character Set Problems
- ASCII Characters
- Unicode: ASCII Control Characters ␀
- Why You Need to Understand ASCII (2024)
- Programing Language: ASCII Char Jam vs Unicode (2011)
- Emacs Lisp Doc String Curly Quote Controversy (2015)
- Linux: Terminal Control Sequence Keys
- Stack Overflow offline page 2011-08-06
- Emacs: Newline Convention
- Emacs Key Notations Explained (/r, ^M, C-m, RET, <return>, M-, meta)