Intro to Wolfram Language Pattern Matching for Lisp Coders (2008)
This page is a intro of pattern matching in Mathematica, and shows its nested syntax in comparison to lisp.
Cortez wrote:
I need to traverse a list of lists, where each sublist is labeled by a number, and collect together the contents of all sublists sharing the same label. So if I have the list -
((0 a b) (1 c d) (2 e f) (3 g h) (1 i j) (2 k l) (4 m n) (2 o p) (4 q r) (5 s t))where the first element of each sublist is the label, I need to produce -
((a b) (c d i j) (e f k l o p) (g h) (m n q r) (s t))I do this with the following -
(defun test (list) (loop for j in list for index = (first j) for k = (rest j) with indices = nil if (not (member index indices)) do (pushnew index indices) and collect k into res else do (nconc (nth index res) k) finally (return res))) I suspect that there is a more efficient and elegant way of doing this, however. Any suggestions welcome.
Brief background: this is part of a program I've written for reading data from SDIF files, a binary format which stores sound description data. The labeled lists represent partials in spectral analysis data (partial-index, time, frequency).
Here's how you can do it in Mathematica.
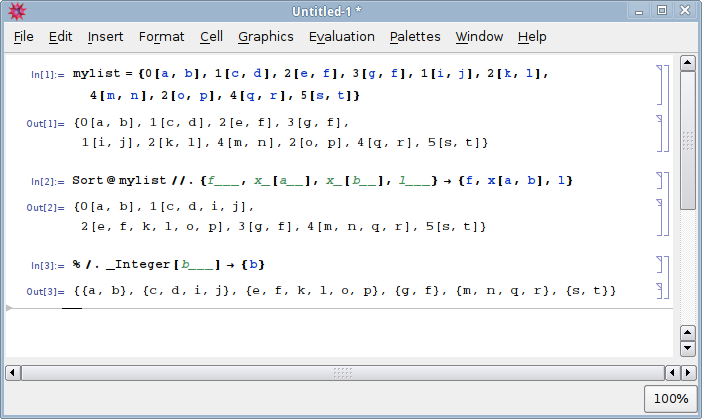
define the list:
mylist = {0[a,b], 1[c,d], 2[e,f], 3[g,f], 1[i,j], 2[k,l], 4[m,n], 2[o,p], 4[q,r], 5[s,t]}
then do this:
Sort@mylist //. {f___, x_[a__], x_[b__], l___} -> {f, x[a,b], l}
output is:
{0[a, b], 1[c, d, i, j], 2[e, f, k, l, o, p], 3[g, f], 4[m, n, q, r], 5[s, t]}
if you want the result cleaned up so that the integer labels are removed, do like this
result /. _Integer[b___] -> {b}
output:
{{a, b}, {c, d, i, j}, {e, f, k, l, o, p}, {g, f}, {m, n, q, r}, {s, t}}
How Does it Work
In Mathematica, ALL syntax has the form f[…], where the text inside are one or more f[…], separated by comma. This is isomorphic to lisp's (f …). But also, most commonly used functions have a shorthand notation. For example, Plus[3,4] can be written as 3 + 4.
The sort@mylist is syntactically equivalent to Sort[mylist].
Any expression of the form f[x] can be written using prefix notation f@x. The result of sort is:
{0[a, b], 1[c, d], 1[i, j], 2[e, f], 2[k, l], 2[o, p], 3[g, f], 4[m, n], 4[q, r], 5[s, t]}
Now we do //. {f___, x_[a__], x_[b__], l___} -> {f, x[a,b], l}.
This is replacement by pattern matching. It means,
if adjacent elements have the same head, merge them into one.
In Regular Expression , a pattern works on text, and output text. In Mathematica, pattern matches list structure, and output a list. (Mathematica also support regex, of course.) Because every expression in Mathematica is a list (like lisp), so pattern matching basically transform expressions. You can think of this as structural transformation, or as advanced lisp macros mechanism.
The outline of the syntax for structural transformation used above is this:
myExpr //. myPattern -> myNewForm
The “myExpr” is any expression. The “myPattern” is any structural pattern. The “myNewForm” is like the regex's replacement string.
The syntax
myExpr //. myPattern -> myNewForm
can also be written in FullForm (which is like lisp's nested syntax), like this:
ReplaceRepeated[myExpr, Rule[myPattern, myNewForm]]
Pattern Syntax
Now, here's some pattern syntax:
_means any single symbol. FullForm syntax isBlank[].__means any 1 or more symbols. FullForm syntax isBlankSequence[].___means any 0 or more symbols. FullForm syntax isBlankNullSequence[].
Now, sometimes you need to attach a name to a pattern, similar to regex's named pattern, for example: (?P<fileName>[-_.a-z]+).
• x_ is a syntax shortcut for Pattern[x, Blank[]], meaning it is a pattern, to be named “x”, and the pattern is Blank[],
means match any single symbol.
We name the pattern so later you can refer to the captured element as “x”.
• f___ is a syntax shortcut for Pattern[f, BlankNullSequence[]].
It means a pattern, to be named “f”, that matches 0 or more elements.
• The x_[a__] means basically a expression with 1 or more elements. The head we named “x”, and its elements we named “a”. FullForm syntax is Pattern[x, Blank[]][Pattern[a, BlankSequence[]]]. Similar for x_[b__].
So, all together, {f___, x_[a__], x_[b__], l___} matches a list and capture neighbors that have the same head.
Now, the replacement expression {f, x[a, b], l} is the new form we want. Note the {f, x, a, b, l} are just names we used for the captured pattern.
So now, Sort[mylist] //. {f___, x_[a__], x_[b__], l___} -> {f, x[a, b], l} gives us the desired result.
Now to remove the head of integer labels, we use another pattern replacement, like this:
result /. _Integer[b___] -> {b}
The _Integer[b___] means any list whose head is “Integer”, and its elements we name “b”. Any expression matching it is replaced by a list of its elements, expressed as {b}.
Purely Nested Form: FullForm vs sexp
This whole expression:
Sort@mylist //. {f___, x_[a__], x_[b__], l___} -> {f, x[a, b], l}
is syntactically equivalent to this:
ReplaceRepeated[ Sort[mylist], Rule[ List[ Pattern[f, BlankNullSequence[]], Pattern[x, Blank[]][Pattern[a, BlankSequence[]]], Pattern[x, Blank[]][Pattern[b, BlankSequence[]]], Pattern[l, BlankNullSequence[]]], List[f, x[a, b], l] ] ]
The syntax is isomorphic to lisp's nested syntax (aka sexp). Lisp equivalent would be like this:
(ReplaceRepeated (Sort mylist) (Rule (List (Pattern f (BlankNullSequence)) ((Pattern x (Blank)) (Pattern a BlankSequence)) ((Pattern x (Blank)) (Pattern b BlankSequence)) (Pattern l (BlankNullSequence))) (List f (x a b) l) ) )
That's some power of fully nested, REGULAR, syntax. (Note: lisp's syntax is not 100% regular. Mathematica's FullForm is. See: Fundamental Problems of Lisp, Syntax Irregularity (2008).)
Solutions in Perl, Python, Ruby, Lisp, Scheme
Scheme Lisp
Sourav Mukherjee supplies this purely functional solution in R5RS Scheme lisp.
;; 2010-09-25 ;; The following is a solution using R5RS Scheme lisp to solve a lisp processing problem. ;; By Sourav Mukherjee sourav.work gmail ;; The problem is described in detail here: http://xahlee.org/UnixResource_dir/writ/notations_mma.html ;;input -> ((0 a b) (1 c d) (2 e f) (3 g h) (1 i j) (2 k l) (4 m n) (2 o p) (4 q r) (5 s t)) ;;output -> ((a b) (c d i j) (e f k l o p) (g h) (m n q r) (s t)) (define (make-pair a b) (cons a b)) (define (number pair) (car pair)) (define (second pair) (car (cdr pair))) (define (third pair) (car (cdr (cdr pair)))) ;;cons second and third elements of short-lst to lst (define (cons-second-and-third-to short-lst lst) (cons (second short-lst) (cons (third short-lst) lst))) (define (take-and-remove n lstlst) (cond ((null? lstlst) (make-pair '() '())) ((= (number (car lstlst)) n) (let ((rest (take-and-remove n (cdr lstlst)))) (make-pair (cons-second-and-third-to (car lstlst) (car rest)) (cdr rest)))) (else (let ((rest (take-and-remove n (cdr lstlst)))) (make-pair (car rest) (cons (car lstlst) (cdr rest))))))) ;; > (take-and-remove 1 '((1 a b) (1 c d) (2 e f) (1 g h) (4 i j))) ;; ((a b c d g h) (2 e f) (4 i j)) ;; > (take-and-remove 2 '((0 u v) (1 a b) (2 c d) (2 e f) (1 g h) (2 i j))) ;; ((c d e f i j) (0 u v) (1 a b) (1 g h)) ;; > (take-and-remove 5 '((0 u v) (1 a b) (2 c d) (2 e f) (1 g h) (2 i j))) ;; (() (0 u v) (1 a b) (2 c d) (2 e f) (1 g h) (2 i j)) ;; > (take-and-remove 5 '()) ;; (()) ;;THIS is the function we want (define (f lstlst) (cond ((null? lstlst) '()) (else (let ((answer-yet (take-and-remove (number (car lstlst)) (cdr lstlst)))) (cons (cons-second-and-third-to (car lstlst) (car answer-yet)) (f (cdr answer-yet))))))) ;; > (f '((1 a b) (1 c d) (2 e f) (1 g h) (4 i j))) ;; ((a b c d g h) (e f) (i j)) ;; > (f '((0 u v) (1 a b) (2 c d) (2 e f) (1 g h) (2 i j))) ;; ((u v) (a b g h) (c d e f i j)) ;; > (f '((0 a b) (1 c d) (2 e f) (3 g h) (1 i j) (2 k l) (4 m n) (2 o p) (4 q r) (5 s t))) ;; ((a b) (c d i j) (e f k l o p) (g h) (m n q r) (s t))
Common Lisp
;; common lisp. by Volkan YAZICI (let ((table (make-hash-table))) (mapcar (lambda (key) (gethash key table)) (mapcar (lambda (item &aux (key (first item))) (setf (gethash key table) (nconc (gethash key table) (rest item))) key) '((0 a b) (1 c d) (2 e f) (3 g h) (1 i j) (2 k l) (4 m n) (2 o p) (4 q r) (5 s t))))) ;; ((A B) (C D I J) (E F K L O P) (G H) (C D I J) (E F K L O P) (M N Q R) (E F K L O P) (M N Q R) (S T))
;; Common Lisp. by Kaz Kylheku, 2008-07-2 ;; If the labels are within a small numeric range, like 0 to 99, you could use an array instead of hashing: (defun join (list) (let ((array (make-array '(100)))) (dolist (sublist list (coerce (remove nil array) 'list)) (destructuring-bind (numeric-label &rest items) sublist (setf (aref array numeric-label) (append (aref array numeric-label) items)))))) ;; Change APPEND to NCONC for the destructive version.
Ruby
# -*- coding: utf-8 -*- # Ruby # by William James, 2008-09-16 [[0,"a","b"],[1,"c","d"],[2,"e","f"],[3,"g","h"],[1,"i","j"], [2,"k","l"],[4,"m","n"],[2,"o","p"],[4,"q","r"],[5,"s","t"]]. sort.inject([]){|a,b| (a==[] or b[0] != a[-1][0]) ? a << b : ( a[-1] += b[1..-1] ; a ) }. map{|a| a[1..-1] } # [["a", "b"], ["c", "d", "i", "j"], ["e", "f", "k", "l", "o", "p"], ["g","h"], ["m", "n", "q", "r"], ["s", "t"]]
Here's the original thread where this problem was posted on comp.lang.lisp: Source groups.google.com
Here's a thread in 2010-09, with solutions in {Perl, Python, Ruby, Lisp, Scheme} At http://groups.google.com/group/comp.lang.python/browse_frm/thread/915b97486f36970d#
Qi Lang
Here's the solution in Qi lang, from its creator Mark Tarver. (Source groups.google.com)
(define group L -> (map (grouph L) (rd (map head L)))) (define grouph [] _ -> [] [[X | Y] | Z] X -> (append Y (grouph Z X)) [_ | Y] X -> (grouph Y X)) (define rd [] -> [] [X | Y] -> (if (element? X Y) (rd Y) [X | (rd Y)])) (group [[0 a b] [1 c d] [2 e f] [3 g h] [1 i j] [2 k l] [4 m n] [2 o p] [4 q r] [5 s t]]) [[a b] [g h] [c d i j] [e f k l o p] [m n q r] [s t]]