Variable Naming. English Words Considered Harmful
Knuth's literate programing wants to turn code into human prose. I want to turn code into symbolic logic.
This page is some thoughts on variable naming in writing computer programs.
In emacs lisp, i usually use camelCase for my local variables. Here's a example:
(defun read-lines (filePath) "Return a list of lines of a file at FILEPATH." (with-temp-buffer (insert-file-contents filePath) (split-string (buffer-string) "\n" t)))
Some lisp coder question the use of camelCase, because it is not conventional lisp style. Here's the reason why i'm using camelCase, and some thoughts about naming of variables.
Variable Naming: Distinction from Language Builtin Words
It provides a easy way to distinguish variables from built-in symbols. Particularly because of the fact that emacs-lisp-mode's coloring scheme is not full.
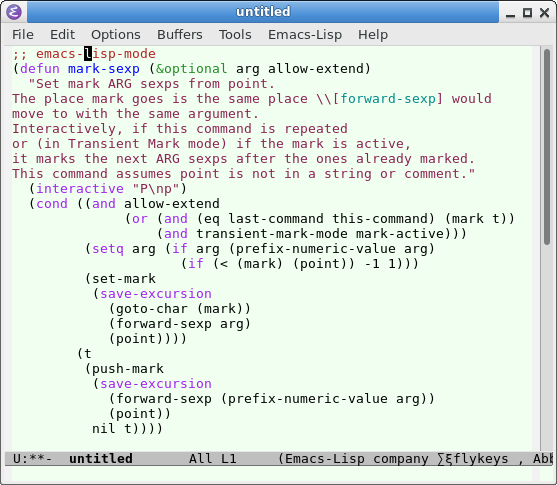
In particular, all my local variables are in camelCase. I could use pot_hole_casing but that's more typing and less visually distinguishable to lisp's hypen-word-style.
Advantage of Unique Names
For variables, in recent years i developed a habit to avoid naming variables that's also a standard English word. So, i'd name “file” as {myFile, aFile}, and “files” might become {fileList, fPaths}. “string” would be {strA, myString, inputStr}.
A ultimate solution for uniqueness is to append a random number in var names. So, “string” would be “str8277”. But the problem with this is that it's too long and disruptive in reading and typing. Recently i've been toying with the idea of attaching a Unicode to all vars. For example, all my var would start with “ξ”. So “string” would be “ξstring”. [see Programing Language: Emoji and Math Symbols in Function Name, Variable, Operator] This solves the random string readability problem. [see Function Parameter names start with phi φ, variable names start with xi ξ (2014)]
My reason to avoid English words is for easy source code transformation, out of practical reasons. (i do a lot search or find and replace in my source code.)
If every name is unique in a project. This way, you could find any variable in the whole project. It makes some aspect easier for debugging and code tracing and code management. It also makes refactoring easier.
The idea is similar to the idea of Referential transparency (computer science). (Referential transparency can be thought of as a notion of find and replace of function and values.)
The desire to have unique identifier in source code comes in many guises. At the extreme is a desire to eliminate variables completely. For example: if every variable in source code can be unique, then much of the desire for lexical scope over dynamic scope is gone. Some namespace problem is also solved. (in particular, elisp does not support namespace.)
Combinatory logic is a desire to get rid of variables from lambda calculus. “Point-free programing” is a invention of syntax for defining functions without the need to write out its formal parameter. [see What is Point-free Programing? (point-free function syntax) (2010)] Unique variable name is also the impetus for Hygienic macro .
[see Windows CLSID GUID UUID]
Variable Name: English Prose vs Symbolic Logic
Another reason that somewhat pushed me in this naming experiment is that… instead of naming your vars in some meaningful English words, the opposite is to name them completely abstractly, as in math's x, y, z, α, β, γ.
So, i'd name “counter” or “num” as just “i” or “n”. (since these are 1-letter string and too common, so with the unique naming idea above, i usually name them “ii” or “nn” or might be “ξi”)
The idea with abstract naming is that it forces you to understand the code as a math expression that specify algorithm, instead of like English prose. Readability of source code is helped by coding in a pure functional programing style (For example, functions, input, output), and good documentation of each function. So, to understand a function, you should just read the doc about its input output. While inside a code snippet, it is understood by simple functional style programing constructs.
To view this idea in another way … when you read math, you never see mathematician name their variables with a multi-letter descriptive word, but usually a single symbol (a, b, c, x, y, z, α, β, γ …), yet there is no problem understanding the expression. Your focus and understanding is on the abstract process and structure.
English Prose Style
To illustrate from the opposite view, the problem with English naming is that often it interfere with what the code is actually doing. For example, in normal convention often you'll see names like {thisObject, thatTree, fileList, files}, your focus is on the meaning of these words, but not what the data type actually are or the function's actual mathematical behavior. The words can be deceptive. For example, “file” can be a file handle, file path, file content. This is especially a problem when you are reading source code of a lang you do not know. For example, when you encounter the word “object”, you don't know if that's a keyword in the language, a keyword in its pattern matching syntax, a keyword for datatype, or just a user defined name that can be arbitrary. When you read a normal source code, half of the words are like that unless the editor does syntax coloring that distinguish the language's keywords.
For example, here's a elisp code with naming following elisp convention:
(defun do-something-region (begin end) "Prints region beginning and ending positions." (interactive "r") (message "Region begins: %d, end at: %d" begin end) )
Are you familiar with elisp? If not, you wouldn't know what those “begin” and “end” are. Maybe they are built-in keywords and have significance to the construct, and if you change them, the code wouldn't work.
But if the code is like this:
(defun do-something-region (φ1 φ2) "Prints region beginning and ending positions." (interactive "r") (message "Region begins: %d, end at: %d" φ1 φ2) )
Then you know that φ1 and φ2 are probably just arbitrary names, because, languages typically only use English words for their keywords.
A Example in Emacs Lisp
Here is a example from emacs lisp source code showing the usefulness of using math symbols in {function, variable} naming. (GNU Emacs 24.3.1, “color.el”)

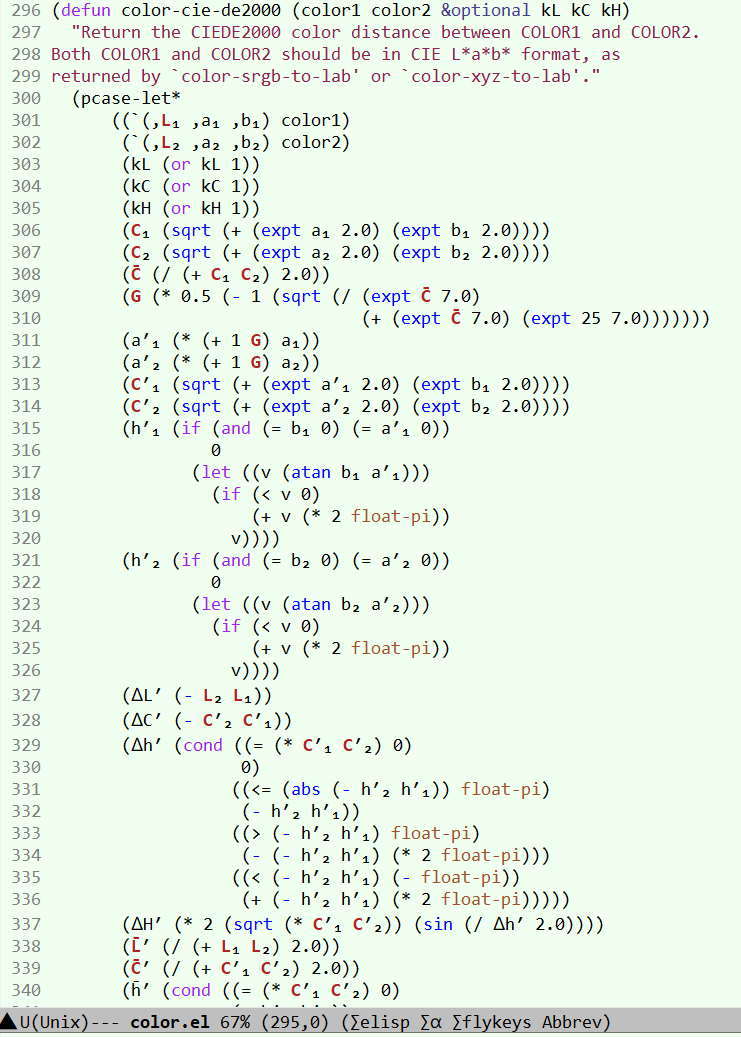
Two Types of Character Sequence in Source Code
Source code is a sequence of characters. When reading source code, you see symbols (operators) and identifiers (function names, var names, keywords.). Among the identifiers, it can be divided into 2 types:
- Those that cannot be changed without affecting the meaning of the program.
- Those that are arbitrary and can be changed.
The ones in the first category are language keywords. For example, {for, while, class, function, extends, Class, this, self, public, static, System, from, begin, end, map, require, import, let, list, defun, lambda, Take, Pattern, Table, Blank, etc} These are the words in the source code that are critical, and they are almost always English words. To be able to know at a glance which words are lang keywords in a source code greatly helps in understanding, especially when you do not know the language well yet. This particularly applies to non-mainstream languages, for example: OCaml, PowerShell, Haskell, Erlang, Mathematica, LSL, etc.
The above ideas is just a experiment. Without actually doing it, you never know what's really good or bad.
This essay is originally a post in comp.lang.lisp At
- http://groups.google.com/group/comp.emacs/msg/2069bc223de679fe
- Newsgroups: comp.emacs, comp.lang.lisp
- From: Xah Lee [xah...@gmail.com]
- Date: Fri, 11 Mar 2011 03:48:32 -0800 (PST)
- Local: Fri, Mar 11 2011 6:48 am
- Subject: naming of variables
What Happens When You Name Your Functions/Variables as Math Symbols?
It's been close to a year since i wrote the article. I've done some experiment. Here's a short report.
In the article, i expressed a few points:
- (1) explore coding in a symbolic logic style: have all function and variable names as meaningless symbols.
- (2) The benefits of unique identifiers.
- (3) The benefits of distinction of language keywords vs user-defined words.
- (4) The fact that naming of function/variables have absolutely nothing to do with how the program behaves.
These can be viewed from language design perspective, or from practical programing perspective.
For (1), i've tried to name all functions and variables to be meaningless symbols, as in math. This turned out to be practically impossible, for any code that's more than 100 lines. (go ahead, you should try it on your own code. You'll get a better understanding of many issues and details only if you try it yourself.) This is easy to see. Just look at some official doc, for example, this JavaScript array methods: JS: Array Methods. Look at all the method names. Imagine if all of them are like {α, β, χ, δ, etc}. You can see that source code like that is completely incomprehensible.
There is a important revelation for me: Naming powers ~99% of documentation, regardless how rich or complete are other forms of proper documention.
This finding has important ramifications with the fact that naming has nothing to do with how the program behaves. To a compiler, naming serves the purpose of identifiers, ID. To human, it serves as documentation, a way to understand the code. These two purposes are completely distinct.
How much programer time or code error have been wasted by misleading name? [see Quality of Terminology In Computer Languages (2008)]
The other realization from this is: for languages to use meaningless symbol as function/variables names, the language must be specifically designed. You can't do this and expect readable source code in Perl, Ruby, Python, Lisp, JavaScript, Java, etc. One example that does this is APL. Here's sample APL code from Wikipedia:
life←{↑1 ⍵∨.∧3 4=+/,¯1 0 1∘.⊖¯1 0 1∘.⌽⊂⍵}
[see APL Symbols Meaning and Code Example]
For (2) (the benefits of unique identifiers) and (3) (The benefits of distinction of language keywords vs user defined words.), these benefits are still there, but there is no standard solution. Note that globally unique identifiers is commonly needed.
- Git went with SHA-1.
- Microsoft and others use CLSID, UUID. [see Windows CLSID GUID UUID]
- Java went with domain name system. [see Jargon: Lisp-1 vs Lisp-2 (Single Value Space vs Multi Value Space)]
Sigils war, special chars in variable names as syntactic type system
- Variable Naming. English Words Considered Harmful
- The Sigil War, Syntactic Indicator for Types of Function and Variable (2016)
- Function Parameter names start with phi φ, variable names start with xi ξ (2014)
- Emacs Lisp Coding Style. DOLLAR SIGN $ and AT SIGN @ in Variable Names
- Jargon: Predicate in Programing Languages (2014)
- Syntactic Meaning of Variable (2018)
- Perl: Variable Name Prefix (aka Sigil)
- Ruby: Variable Name Conventions
- PowerShell: Variable
- Clojure: Variable Name Conventions (sigil. macro magic characters.)