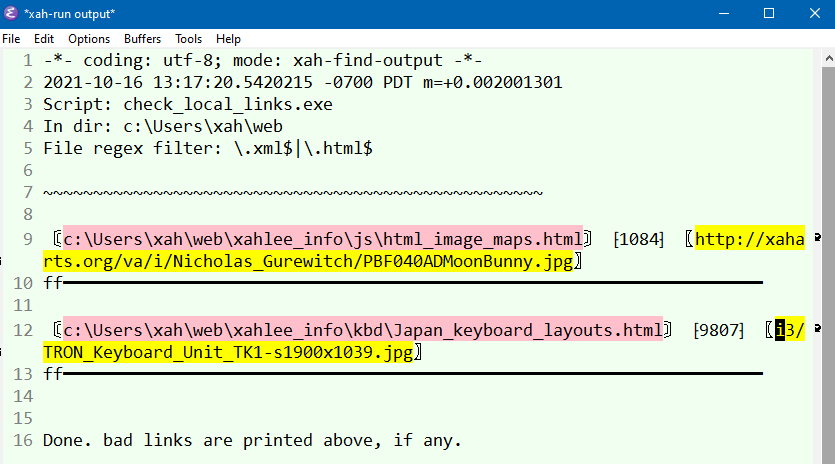
Golang: Validate Website Local Links 📜
Here's a script that check all local links and inline image links in the html files of a given directory. Print a report.
/* File name: check_local_links.go Description: given a dir, check all local links and inline image links in the html files. Print a report. In emacs, you can M-x xah-find-output-mode from xah-find.el to make it pretty and jump to links website: http://xahlee.info/golang/golang_validate_links.html Created: 2018-11-24 Version: 2025-07-06 */ package main import ( "fmt" "io/fs" "os" "path/filepath" "regexp" "strings" "time" "unicode/utf8" ) /* used for checking if a link is not in this dir, it's considered bad link. */ var webroot = "c:/Users/xah/web/" /* inputDir is dir to start. Must be full path. If it's a file, the parent dir is used inputDir must be in webroot */ var inputDir = "c:/Users/xah/web/" // var inputDir = "c:/Users/xah/web/xahlee_info/comp/" const fnameRegex = `\.xml$|\.html$` // dir to ignore. each is a dir name. not regex var dirsToSkip = []string{ ".git", } // check the file only if file content match this regex var contentCheckRegex = `.` // s------------------------------ var xtable = fbuilt_table(filepath.ToSlash(filepath.Clean(webroot)), dirsToSkip) const fileSep = "==file=sep=M6bcX=====================================" const occurBracketL = '⦋' const occurBracketR = '⦌' const posBracketL = '⁅' const posBracketR = '⁆' const fileBracketL = '❬' const fileBracketR = '❭' // s------------------------------ /* return true if link start with http and is xahlee's domain */ func isXahDomain(linkVal string) bool { var isXahSite, errxs = regexp.MatchString(`^http://ergoemacs.org|^http://wordyenglish.com|^http://xaharts.org|^http://xahlee.info|^http://xahlee.org|^http://xahmusic.org|^http://xahsl.org/`, linkVal) if errxs != nil { panic(errxs) } return isXahSite } /* change a http URL to file full path eg http://xahlee.info/index.html becomes c:/Users/xah/web/xahlee_info/index.html or return as is */ func fUrlToFilePath(xurl string) string { var xx = xurl xx = strings.Replace(xx, "http://ergoemacs.org/", "c:/Users/xah/web/ergoemacs_org/", 1) xx = strings.Replace(xx, "http://wordyenglish.com/", "c:/Users/xah/web/wordyenglish_com/", 1) xx = strings.Replace(xx, "http://xaharts.org/", "c:/Users/xah/web/xaharts_org/", 1) xx = strings.Replace(xx, "http://xahlee.info/", "c:/Users/xah/web/xahlee_info/", 1) xx = strings.Replace(xx, "http://xahlee.org/", "c:/Users/xah/web/xahlee_org/", 1) xx = strings.Replace(xx, "http://xahmusic.org/", "c:/Users/xah/web/xahmusic_org/", 1) xx = strings.Replace(xx, "http://xahsl.org/", "c:/Users/xah/web/xahsl_org/", 1) return xx } // s------------------------------ // stringMatchAnyRegex return true if xst is matched by any regex in regexlist. // version 2018-09-01 func stringMatchAnyRegex(xst string, regexlist []string) bool { for _, re := range regexlist { result, err := regexp.MatchString(re, xst) if err != nil { panic(err) } if result { return true } } return false } // strInArray return true if x equals any of y // version 2018-11-12 func strInArray(x string, y []string) bool { for _, v := range y { if x == v { return true } } return false } func isFileExist(fpath string) bool { if _, err := os.Stat(fpath); os.IsNotExist(err) { return false } return true } /* remove fractional part of url. eg remove #... version 2018-11-12 */ func removeFrac(url string) string { var x = strings.LastIndex(url, "#") if x != -1 { return url[0:x] } return url } /* getLinkIndexes return all links from a html file in the format [pos1 pos2]. The position are index in byte slice, between them is a link, e.g. i/cat.png The return value looks like this [[ 100 108] ...] created: 2018-11-24 version: 2025-07-06 */ func getLinkIndexes(textbytes []byte) [][]int { var result = make([][]int, 0, 300) // var xopeningTagRegex = (regexp.MustCompile(`<[A-Za-z][A-Za-z0-9]* [^<>]+>`)) var xopeningTagRegex = (regexp.MustCompile(`<(?:a|img|script|link|iframe|video|audio|source|picture|object|input|embed|form|base) (?:[^>])+>`)) for _, indexPairs := range xopeningTagRegex.FindAllIndex(textbytes, -1) { var openingTag = textbytes[indexPairs[0]:indexPairs[1]] for _, v2 := range (regexp.MustCompile(` (?:href|src|poster|xml:base|xmlns)="([^"]+)"`)).FindAllSubmatchIndex(openingTag, -1) { if 0 != len(v2) { var x = []int{ indexPairs[0] + v2[2], indexPairs[0] + v2[3], } result = append(result, x) } } } return result } /* printBad report bad links fileFullPath is the full path of the file the link occur linkPath is full path of the link linkVal is value that occur in href= or src= */ func printBad(fileFullPath string, linkPath string, linkVal string, startPos string) error { fmt.Printf("%c%v%c %c%s%c %c%s%c\n", fileBracketL, fileFullPath, fileBracketR, posBracketL, startPos, posBracketR, occurBracketL, linkVal, occurBracketR) fmt.Println(fileSep, "\n") return nil } /* return true if link is good. linkVal is value of href or src etc. linkPath is file fullpath. pagepath is file the links are from. */ func isLinkGood(linkVal string, linkPath string, pagepath string) bool { // link val cannot start with these, even file exist if strings.HasPrefix(linkVal, "file://") || strings.HasPrefix(linkVal, "c:/") || strings.HasPrefix(linkVal, "C:/") { return false } _, inhashtable := xtable[linkPath] var inwebroot = strings.HasPrefix(linkPath, webroot) if inhashtable { if inwebroot { return true } else { return false } } else { // fmt.Printf("pagepath %v\n", pagepath) // fmt.Printf("calling file exist linkVal %v\n", linkVal) // fmt.Printf("calling file exist linkPath %v\n", linkPath) return isFileExist(linkPath) } } /* return true if link is to be skipped for checking */ func isSkipLink(linkVal string) bool { var isSkip, errM = regexp.MatchString(`^#|^http://|^https://|^mailto:|^irc:|^ftp:|^javascript:`, linkVal) if errM != nil { panic(errM) } return isSkip } // checkFile, takes a html file path, extract all links, if local link and file does not exist, print it func checkFile(fullpath string) error { textbytes, er := os.ReadFile(fullpath) if er != nil { panic(er) } { var re = regexp.MustCompile(contentCheckRegex) if re.FindIndex(textbytes) == nil { return nil } } var allLinks = getLinkIndexes(textbytes) for _, val := range allLinks { var pos1 = val[0] var pos2 = val[1] var linkVal = string(textbytes[pos1:pos2]) var linkValNoFrag = removeFrac(linkVal) if isXahDomain(linkVal) { if !isLinkGood(linkVal, fUrlToFilePath(linkValNoFrag), fullpath) { printBad(fullpath, fUrlToFilePath(linkValNoFrag), linkVal, fmt.Sprintf("%d", utf8.RuneCount(textbytes[0:pos1]))) } } else { if !isSkipLink(linkVal) { var linkFullPath = filepath.ToSlash(filepath.Clean(filepath.Dir(fullpath) + "/" + linkValNoFrag)) if !isLinkGood(linkVal, linkFullPath, fullpath) { printBad(fullpath, linkFullPath, linkVal, fmt.Sprintf("%d", utf8.RuneCount(textbytes[0:pos1]))) } } } } return nil } /* fbuilt_table build a hashtable of a directory. return a hashtable. key is filename full path. value is 1. result also contain dir paths. xinputdir is a dir full path xignorelist is a array of dir names to ignore. files in these dir are ignored. */ func fbuilt_table(xinputdir string, xignorelist []string) map[string]int { var xmap = make(map[string]int, 47000) var doFile = func(xpath string, xinfo fs.DirEntry, xerr error) error { // first thing to do, check error. and decide what to do about it if xerr != nil { fmt.Printf("error [%v] at a path [%q]\n", xerr, xpath) return xerr } if xinfo.IsDir() { if strInArray(filepath.Base(xpath), xignorelist) { return filepath.SkipDir } else { xmap[filepath.ToSlash(filepath.Clean(xpath))] = 2 } } else { xmap[filepath.ToSlash(filepath.Clean(xpath))] = 1 } return nil } err := filepath.WalkDir(xinputdir, doFile) if err != nil { fmt.Printf("error walking the path %q: %v\n", xinputdir, err) } return xmap } func main() { scriptName, errPath := os.Executable() if errPath != nil { panic(errPath) } inputDir = filepath.ToSlash(filepath.Clean(filepath.Dir(inputDir))) webroot = filepath.ToSlash(filepath.Clean(webroot)) var startime = time.Now() fmt.Println("-*- coding: utf-8; mode: xah-find-output -*-") fmt.Printf("%v\n", startime.Format("2006-01-02 15:04:05.000")) fmt.Printf("Script path: %v\n", filepath.ToSlash(filepath.Clean(scriptName))) fmt.Printf("In dir: %v\n", inputDir) fmt.Printf("File regex filter: %v\n", fnameRegex) fmt.Println() fmt.Println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n") var fwalker = func(xpath string, xinfo fs.DirEntry, xerr error) error { if xerr != nil { fmt.Printf("error 「%v」 at a path 「%q」\n", xerr, xpath) return xerr } xpath = filepath.ToSlash(xpath) if xinfo.IsDir() { if strInArray(filepath.Base(xpath), dirsToSkip) { return filepath.SkipDir } } else { var x, err = regexp.MatchString(fnameRegex, filepath.Base(xpath)) if err != nil { panic("stupid MatchString error 59767") } if x { checkFile(xpath) } } return nil } err := filepath.WalkDir(inputDir, fwalker) if err != nil { fmt.Printf("error walking the path %q: %v\n", inputDir, err) } var endtime = time.Now() var xtimediff = endtime.Sub(startime).Seconds() fmt.Printf("time spend in seconds: %.1f\n", xtimediff) fmt.Printf("\n%v\n", "Done. bad links are printed above, if any.") }