Perl: GET Web Page Content
In Perl, the easiest way to get a webpage is to use the Perl program HEAD or GET usually installed at /usr/bin. e.g. in shell, type:
GET google.com
It'll return the web page content. You can save it to a file by
GET google.com > myfile.txt.
HEADreturns a summary of the page info, such as file size. It is the header lines of server response.GETreturns the full HTML file.
HEAD and GET are two calling methods of the HTTP protocol. The Perl script are named that way for this reason. [see HTTP Protocol Tutorial (2016)]
Here's HEAD example:
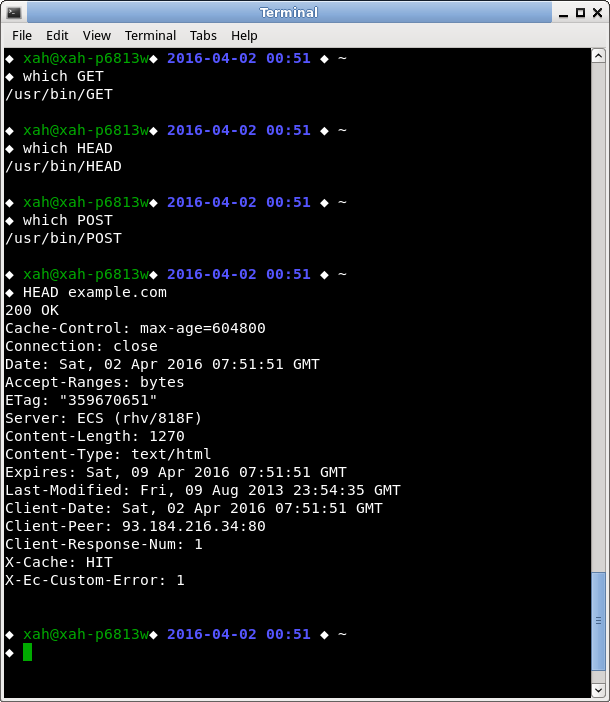
The linux commands {GET, HEAD, POST} are perl scripts.
They are installed on Ubuntu.
You can read their doc by man HEAD.
For more control, use LWP::Simple or LWP::UserAgent. Both of these you need to install.
# get web page content use strict; # use LWP::Simple; use LWP::UserAgent; my $ua = new LWP::UserAgent; $ua->timeout(120); my $url='http://example.com/'; my $request = new HTTP::Request('GET', $url); my $response = $ua->request($request); my $content = $response->content(); print $content;
In the above, the $ua -> timeout(120); is a Object Oriented syntax.