Syntax Design: String Syntax (2010)
This article discuss problems of string syntax in programing languages.
Problem with Escapes
Typically, the syntax for string in a lang look like this:
# perl $xstr = "abc";
However, if your string contains double quote, then you need to escape them (usually with backslash), and this is ugly, hard to read, and inconvenient for programers. For example, suppose your code processes a lot HTML.
It's much worse with regex, especially in emacs lisp.
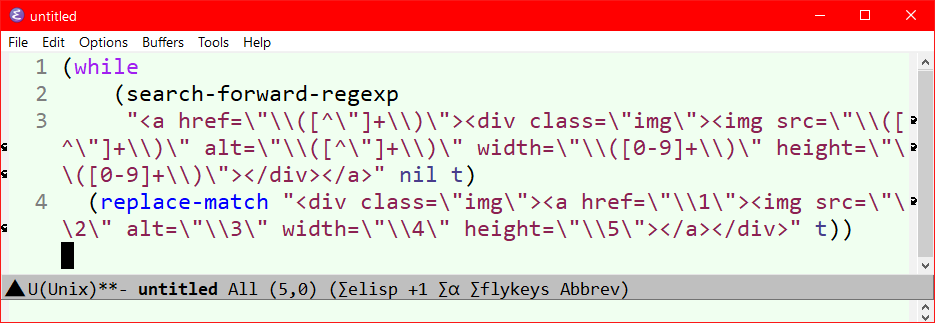
This is called Leaning toothpick syndrome.
Other Forms of Escape: HTML Entities, Hex Code Literals
Another form of escape is HTML entities or hexadecimal code.
For example, in HTML, the ampersand char can be written as & or & or &.
The char “A” can be written as A or A.
Using so-called “entities” is necessary for the chars < > & .
Similarly, in Java and many other langs, hexadecimal code can be used.
For example, “A” can be written as \u0041.
See:
- JS: Unicode Escape Sequence
- Python: Unicode Escape Sequence
- Java: Unicode Character Escape Syntax
- Elisp: Unicode Escape Sequence
Adoptable String Delimiters (Perl, PHP, Python)
One solution is to use different delimiters for the string. Perl, Python, take this approach.
For example, in perl, the following evaluates to the same string:
# perl # all the following are equivalent $x = "abc"; $x = 'abc'; $x = q/abc/; $x = q[abc]; $x = q(abc); $x = q{abc}; $x = qq/abc/; $x = qq[abc]; $x = qq(abc); $x = qq{abc};
Basically, it allows different chars to be used for the string delimiter. so you can avoid escape sequence in the string.
Python also has some way to avoid leaning toothpick syndrome. For example, the following lines all evaluate to the same string:
# python # all the following are equivalent x = "abc" x = 'abc' x = """abc""" x = '''abc''' x = r"abc" x = r'abc' x = r"""abc""" x = r'''abc'''
Here-String (aka Here-Doc)
Another solution, used by Perl and PHP, orignated from unix shell, is called “heredoc”. Basically, it uses a random string as delimiter, and anything in between is literal. Here's a example.
# perl $xstr = <<'WdR62'; <link rel="stylesheet" type="text/css" href="../xyz.css"> WdR62
Can Escape be Completely Avoided?
On 2010-09-26, Ron Garret (http://www.flownet.com/ron/) wrote:
And just for good measure, some «European style quotes» and “balanced smart quotes” which I intend some day to try to convince people to start using to eliminate the scourge of backslash escapes. But that's a topic for another day.
On , Spiros Bousbouras [spi…@gmail.com] wrote:
I don't see how they would help to eliminate backslash escapes. Let's imagine that strings were delimited by « and ». If you wanted a string which contained a » you would still need to escape it.
Using rich varieties of matching pair chars in Unicode can greatly eliminate many escapes and improves code readability. [see Unicode: Brackets 「」【】《》] Compare the following 2 elisp code:
(insert "<span class=\"ref\"><a href=\"" URL "\">" swd "</a></span>")
(insert 「<span class="ref"><a href="」 URL 「">」 swd 「</a></span>」)
if the programing language use a finite set of delimiter variations, then , escape can not be completely eliminated.
This is because, if you lang is a general lang, inevitably it'll be used to parse its own source code. And there will be occasions when the text you want to parse is a complete enumeration of all possible string delimiters of your lang. (For example, a tutorial of language X in HTML containing examples of X and processed by X) So here, doesn't matter what delimiter you choose, it occurs in the string you want to quote.
“heredoc” is a ugly solution to this.
Another possible solution is variable repetition.
For example, consider any repetition of a matching pair delimiter is also a valid syntax:
(((abc))), {{abc}}, 「「「「abc」」」」, etc, or any combination of repetition of variable string delimiters, for example, ([((【《『‹abc›』》】))]).
(Note: here, the desired property is the ability to quote text without modifying the text in any way. So, this excludes adding any form of escapes into the text, or inventive ways such as adding a Tab char in front of each line. Also, am thinking in the context of computer language syntax. This excludes semantic solutions by specifying how many chars/lines to read in and not using any delimiters. Thanks to reddit discussion At http://www.reddit.com/r/programming/comments/fux1s/computer_language_design_string_syntax/ .)
Disadvantage of Variable String Delimiters
The adoptable quoting chars also introduces some complexity. Namely, each delimiter symbol in your lang now has multiple meanings, context dependent, and or, you have multiple symbols for the same semantic. [see Programing Language: ASCII Char Jam vs Unicode (2011)]
For example, one language that does not have multiple string delimiters is emacs lisp (or lisps in general). In emacs lisp, a string is always delimited by the "QUOTATION MARK". Emacs lisp has the worst readability problems of leaning toothpick syndrome. However, one advantage is that string syntax has a very simple logic. For example, you can ALWAYS locate ALL strings in the source code by searching for double straight quote char. In langs with adoptable quotes such as perl, this can no longer be true. You have to search several chars, and for each occurrence you have to judge based on adjacent chars.
Similarly, in Mathematica, paren is used for one single purpose only, always.
It's delimiter for specifing evaluation order of expressions (For example, (3+4)*2).
The square bracket [] has one single purpose only.
It's delimiter for function arguments, for example: f[x_]:= x + 1, f[3].
The curly brackets {} again has one single purpose only.
It's delimiter for list.
For example, {1,2}.
In traditional math notation and most comp langs, it's all context dependent soup.
Doesn't matter which is your philosophy in lang design with regards to quoting mechanism, Unicode introduce many proper matching pairs that are helpful, and avoid multiple semantic meanings for a given char.
- Unicode: Brackets 「」【】《》
- Programing Language: Unicode math symbols in function name, variable, operator
- HTML6, JSON SXML Simplified (2010)
(this essay is originally a post from online forum discussion at Source groups.google.com)