Programing Language: ASCII Char Jam vs Unicode (2011)
Symbol Congestion Problem
Vast majority of computer languages use ASCII as its character set. This means, it jams multitude of operators into about 20 symbols. Often, a symbol has multiple meanings depending on context. Also, a sequence of chars are used as a single symbol as a workaround for lack of symbols. Even for languages that use Unicode as its char set (Java, XML, python, golang), almost all of them only use the ~20 ASCII symbols for all its operators. The only exceptions i know of are Mathematica, Fortress, APL .
This page gives example and problems of symbol congestion.
Symbol Congestion Examples
Multiple Meanings of a Symbol
Here are some common examples of a symbol that has multiple meanings depending on context:
In Java, the SQUARE BRACKET
[
] is used for declaring array type String[].
Also, part of syntax for array initiation xArray = new int[10];.
Also, a delimiter for getting a element of array xArray[i].
In
Java
and most other languages, PARENTHESIS
(
) is used for expression
grouping (x + y) * z, also as delimiter for arguments of a function call System.out.print(x), also as
delimiters for parameters of a function's declaration main(String[] args).
In C, Perl,
JavaScript
, and others, COLON : is used as a separator in a if-expression (e.g. (test ? "yes" : "no")), also as a namespace separator (e.g. use Data::Dumper;).
In URL, SOLIDUS
/ is used as path separator, also as indicator of protocol. e.g. http://example.org/comp/unicode.html
In Python and many others, LESS-THAN SIGN
<
is used for “less than” boolean operator, but also as a alignment flag in its “format” method, also as a delimiter of named group in regex, and also as part of char in other operators that are made of 2 chars, example:
{<<,
<=,
<<=,
<>}.
The above are just some examples to illustrate the issue. There are perhaps 100 times more.
Examples of Multi-Char Operators
Here are some examples of common operators that are made of multiple characters:
||→ Logical OR&&→ Logical AND==→ Equality Testing===→ Sameness Testing!=→ Inequality Testing<=→ Less-or-Equal than Testing>=→ Greater-or-Equal than Testing++→ Increase by One--→ Decrease by One**→ Exponential=+→ Add and Assign=*→ Multiply and Assign:=→ Define::→ Namespace Separator//→ Floor Division..→ Range Operator
Problems of Symbol Congestion
The tradition of sticking to the 95 chars in ASCII of 1960s is extremely limiting. It creates complex problems manifested in the following.
String Escape Mechanism
String Escape mechanism, for example, C's backslash {\n, \r, \t, \/, etc}, widely adopted. A better solution would be Unicode symbols for unprintable chars. Example candidates:
 ␍ ␊ ␉ ↩ ▷
Crazy Toothpicks Syndrome
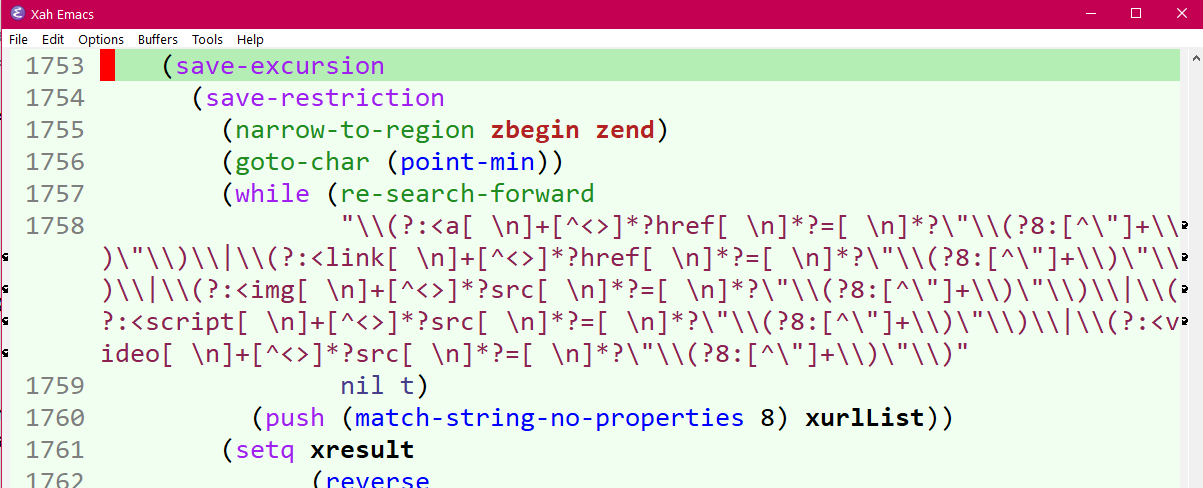
The backslash string escape mechanism directly leads to crazy leaning toothpicks syndrome, especially bad in emacs regex.
Here is a example of a good design, when Unicode characters are used as meta-characters.
before:
"\\(href\\|src\\)=\"\\([^\"]+\\)\""
after:
“〔href∨src〕="〔「¬"」+〕"”
Confusing Context Sensitive Symbols
This is particularly bad in regex. e.g. ^ has multiple meanings depending on where it is placed. If in the beginning, it's a line beginning marker, if as first char inside square brackets, for example: [^…] then it's a negation, otherwise it's literal.
Many other regex chars also have special meaning, some depends on their position. e.g. ^ $ ? | . + \ - { } ( ) [ ] ….
Whether a symbol's meaning is literal, or whether their position changes meaning, or wether meaning is changed inside [], is completely ad hoc.
Complex Delimiters for Strings
The lack of bracketing symbols leads to varieties of unnecessarily complex string delimiters to help solve the problem of quoting.
Python's triple quotes and raw string.
x = 'dog cat bird' x = "dog cat bird" x = r'dog cat bird' x = r"dog cat bird" x = """dog cat bird""" x = '''dog cat bird'''
Perl's varying delimiters:
# perl $x = "abc"; $x = 'abc'; $x = q[abc]; $x = q(abc); $x = q{abc};
Perl, PHP, unix shell's “heredoc”.
HTML Entities

The HTML entities are invented partly as a mechanism of avoiding symbol jam of the characters: < > &, and partly as a kludge for entering frequently needed symbols (e.g. © ™ α → …), and partly as a kludge to avoid char encoding and transmission problem (i.e.
there is no UNICODE in 1980s, and only ASCII and a handful other basic encoding is widely recognized.).
For a concrete example of how this induced complexity in code, see: ASCII Jam Problem: HTML Entities .
When you are writing a tutorial about HTML in HTML, and trying to tell user how to represent the ampersand character, you will have things like this: &amp;. And when you have scripts that process HTML, it gets very complex.
Ampersand in URL, URL Percent Encoding
URL percent encoding and encoding Unicode in URL. Example:
http://en.wikipedia.org/wiki/Saint_Jerome_in_His_Study_%28D%C3%BCrer%29
for
http://en.wikipedia.org/wiki/Saint_Jerome_in_His_Study_(Dürer)
The complexity in resolving the ambiguity of the Ampersand char in URL and CGI protocol.
- URL Percent Encoding and Ampersand Char
- URL Percent Encoding and Unicode (2010)
- JavaScript Encode URL, Escape String
Representation for: Unprintable Character, Their Input Methods, Keyboard Keys
When a language or config needs to represent keystrokes, the ASCII jam made complexities and readibility much worse. See:
e.g. in emacs, you will encounter
\n \r \t \f and ^J ^M ^I ^L and C-m RET <return> Enter ^m control-m 13 (?\C-m).
In Mac OS X's Keybinding system the “DefaultKeyBinding.dict”, you have:
{
"@b" = ("insertText:", "Cmd+b pressed.");
"~a" = ("insertText:", "Opt+a pressed.");
"^b" = ("insertText:", "Crtl+b pressed.");
"^@a" = ("insertText:", "Ctrl+Cmd+a pressed.");
"^~a" = ("insertText:", "Crtl+Opt+a pressed.");
"#2" = ("insertText:", "2 on the number keypad pressed.");
}
!n::Run Notepad ; this means Alt+n ^n::Run Notepad ; this means Ctrl+n +n::Run Notepad ; this means Shift+n #n::Run Notepad ; this means the Win+n
If Unicode is used, some of these problems can be alleviated. ⌘ ⌥ ⎇ ↵ ⇥ ⌫.
Fortress and Unicode
All these problems occur because we are jamming so many meanings into about 20 symbols in ASCII.
Problem of Typing Unicode?
Today, it's trivial to create a keyboard layout to type any set of Unicode symbols you choose. See: How to Create a APL or Math Symbols Keyboard Layout .
Some people may find that typing a character not on keyboard directly is an issue, but that is mostly psychological. Note that in Japanese, Chinese, where there are millions of computer users and programers, every character is typed by a input method.
- Programing Language: Unicode math symbols in function name, variable, operator
- Concepts and Confusions of Prefix, Infix, Postfix and Lisp Notations (2006)
- Syntax: What Are Good Qualities of Computer Language Syntax (2008)
- What is Function, What is Operator. (2010)
- Math Notation, Computer Language Syntax, and the “Form” in Formalism (2003)
Unicode, Encoding, Escape Sequence.
- Unicode Symbol for “e.g.” (exempli gratia)
- Semantics and Symbols: Examples of Unicode Symbols Usage
- Unicode Ellipsis vs Triple Dots
- Programing Language: ASCII Char Jam vs Unicode (2011)
- The use of Unicode Brackets 〈〉《》【】〖〗「」〔〕 (2011)
- Unicode Semantics: the ∀ in Turn A Gundam
- URL Percent Encoding and Unicode (2010)
- URL Percent Encoding and Ampersand Char
- Semantic of Symbols: HTML Entities, Ampersand, Unicode
Programing Language String Syntax Problem
ASCII Character Set Problems
- ASCII Characters
- Unicode: ASCII Control Characters ␀
- Why You Need to Understand ASCII (2024)
- Programing Language: ASCII Char Jam vs Unicode (2011)
- Emacs Lisp Doc String Curly Quote Controversy (2015)
- Linux: Terminal Control Sequence Keys
- Stack Overflow offline page 2011-08-06
- Emacs: Newline Convention
- Emacs Key Notations Explained (/r, ^M, C-m, RET, <return>, M-, meta)